
Michal Šmiraus
Fakulta aplikované informatiky
Ústav počítačových a komunikačních systémů
e-mail: smiraus@fai.utb.cz
ABSTRAKT
Potřeba efektivního vyhledávání informací je ve svém prvotním významu pouze jedním, ale rozhodně strategickým aspektem úspěchu v novodobém prostředí. Díky pokročilým metodám vyhledávání a vytěžování informačních či znalostních zdrojů, nám nové pohledy na jejich vzájemné kombinace poskytují dosud nevídané možnosti. Kde však leží hranice mezi unikátním, kdanému požadavku relevantním údajem a uměle vytvořeným shlukem prostých dat bez faktického obsahu? Budou vbudoucnu moderní vyhledávací stroje znát odpověď na každou naši otázku?
ABSTRACT
The need for effective information search is in its initial meaning only one, but definitely a strategic aspect of the success in the modern environment. With advanced methods of search and extraction of information and knowledge resources, our new insights into their combinations provide unprecedented opportunities. But where is the boundary between the unique, given the requirement for relevant data and artificially generated cluster-data without the actual content? Will the future of modern search engines know the answer to our every question?
ÚVOD
Žijeme ve společnosti znalostí, kdy schopnost rychlého vyhledání relevantní informace patří mezi konkurenční výhody a nezáleží přitom, v jakém oboru pracujeme. Společně sezvýšenou dostupností rozličných informačních zdrojů vprostředí internetu dochází kneustále sílícímu tlaku na jejich relevantní třídění a uspořádání, přičemž přímá úměra mezi množstvím poskytovaných informací a počtem způsobů jejich efektivního vytěžování prakticky neexistuje. Více než 15 miliard je podle posledních odhadů [1] množství vsoučasnosti dostupných statických dokumentů pomocí služby World Wide Web, přičemž minimálně trojnásobný objem tvoří dokumenty uložené vdatabázích, mající webové rozhraní (tzv. oblast neviditelného webu).
ČLOVĚK A STROJ – SPOLEČNÝ BOJ ZA RELEVANTNÍ OBSAH
Klíčová slova a dotazování se vnich jsou dnes bezesporu tím nejčastěji používaným způsobem vyhledávání informací prostřednictvím webových vyhledávacích nástrojů – vyhledavačů. Výsledkem tohoto postupu však nutně nemusí být jen relevantní výsledky spřesně cílenými dokumenty vpopředí. Při použití vpraxi užívaných metod booleovského či vektorového modelu vyhledávání, sřazením výsledků podle vztahů mezi dokumentem a dotazem, se snadno může stát, že vyhledávací stroj, což je navigační mechanizmus budovaný na základě automatizovaného sběru dat, vyhodnotí indexovaný dokument nesprávně, tedy přiřadí dokumentu jinou váhu a prioritu, než jaká mu ve skutečnosti přísluší.
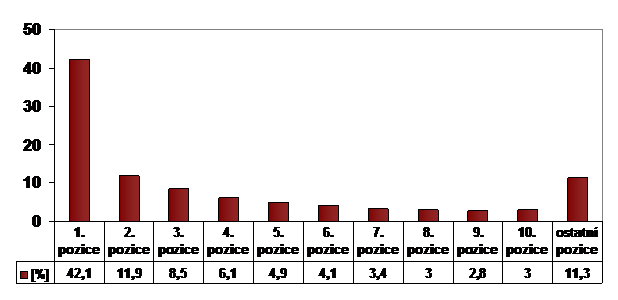
Tab. 1 – Procentuální míra „prokliku“ odkazových pozic ve výsledcích vyhledávání
Statisticky vzato, uživatelé současných webových vyhledávačů, coby moderních technických nástrojů pro získávání informací zprostředí internetu, mají tendenci zabývat se pouze výsledky na první nabízené stránce vyhledávání (zpravidla nejčastěji prvních 10 odkazových pozic), v důsledku čehož se při zohlednění této skutečnosti snaží autoři zejména komerčně zaměřených serverů ovlivňovat pořadí svých odkazů ve výsledcích vyhledávání a následně znich profitovat.
Tento trend se stal dlouhodobým problémem předních světově uznávaných vyhledávacích strojů, kterému je třeba čelit pravidelnými aktualizacemi a dalším vývojem či úpravou stávajících vyhledávacích algoritmů, neboť jinak by zuživatelského hlediska dramaticky klesala věrohodnost takto poskytovaných výsledků.
Hlavním problémem současnosti vtomto ohledu jsou tzv. MFA (Made for AdSense) weby nebo obsahové či linkové farmy, což jsou v souhrnu zpravidla čistě pro reklamní a marketingové účely vytvořené webové stránky se shluky klíčových slov, s obsahem nevypovídající hodnoty či svelkým množstvím nerelevantních odkazů, jejichž společným cílem je snaha ozáměrné ovlivňování pořadí webů v jednotlivých internetových vyhledávačích. Proto např. Google nedávno představil novou revoluční verzi hodnotícího algoritmu indexovaných stránek Panda/Farmer update, kterou spouští prozatím pouze pro americký region, nicméně podle předpokladů tento update časem ovlivní téměř 12% všech hledání [2], a to sjediným cílem – vymýtit nekvalitní obsah a dát prostor fakticky hodnotným informačním zdrojům.
KDO SE KOMU PŘIZPŮSOBÍ ?
Vlivem zmiňovaného tlaku na umístění leckdy nerelevantních dokumentů na předních pozicích výsledků vyhledávání se dnes při tvorbě webového obsahu snaží většina tvůrců volně dostupného obsahu především o jeho maximální přizpůsobení zhlediska „atraktivity“ pro samotné vyhledávacími stroje. Není však již daleko doba, kdy postupným zdokonalováním modelové architektury těchto vyhledávacích strojů dojde naopak k většímu zohlednění většinového lidského přístupu kvyhledávání. Co je dobré pro vyhledávací stroj, nemusí být dobré pro člověka, neboť je to především vyhledávací stroj samotný (reprezentovaný často pečlivě utajovaným vyhledávacím algoritmem), který lze vpřípadě potřeby relativně snadno měnit či modifikovat, zatímco fungování masy lidí a jejich zvyklostí již tak jednoduše měnit nelze. Sdlouhodobější perspektivou do budoucna lze tedy očekávat spíše sílící tlak na přizpůsobení architektury moderních vyhledávacích strojů lidskému uvažování a chápání.
Ani toto však také nebude dost dobře možné bez toho, aniž by se uživatelé webových vyhledávacích strojů i vbudoucnu alespoň částečně nepřizpůsobovali jejich syntaktickému jazyku. Největším nepřítelem vboji za nacházení relevantního obsahu při uživatelském vyhledávání, je dnes především uživatel sám. Vlastním průzkumem a dotazováním [3] mezi uživateli webových vyhledávacích strojů byl potvrzen obecně známý předpoklad a sice, že valná většina z nich využívá rozšířené možnosti moderních fulltextových vyhledávačů (booleovské operátory, filtry apod.) jen ve velmi omezené míře a vzásadě zminima vložených vstupních údajů (krátkých dotazů), je očekáván maximálně relevantní a přesný výsledek vyhledávání.
|
Zkoumaný údaj: |
Průměrná hodnota: |
|
Počet slov v dotazu |
2,46 |
|
Počet operátorů dotazu |
0,48 |
|
Počet dotazů/uživatele |
2,13 |
|
Počet stran výsledků |
1,16 |
Tab. 2 – Hodnocení přístupu uživatelů webových vyhledávacích strojů při vyhledávání informací
Hlavním problémem na straně vyhledávacích strojů je tedy vsoučasnosti především získání dostatečného informačního potenciálu i zjinak krátkých dotazů, které jeho uživatelé zadávají, nemají snahu dotazy ladit a také nemají trpělivost výsledek podrobněji prohlížet.
Vzhledem ktomu, že se většina uživatelů snaží najít hledané informace co nejrychleji, často také raději krom obvyklého jedno či dvou slovného spojení volí přístup použitím otázky vpřirozeném jazyce namísto přetvoření hledaného výrazu do podoby syntaxe jazyka dotazovacího, což částečně souvisí súrovní informační gramotnosti, čemuž odpovídá i procentuálně nižší zastoupení uživatelů, kteří po zadání dotazu nedostávají vždy kýženou odpověď na to, co hledají. Stím také přímo souvisí idalší významný negativní aspekt– polysemie (tj. mnohovýznamnost slov), která ovlivňuje především přesnost, tedy podíl skutečně relevantních odpovědí ve výsledkovémnožině vyhledávání.
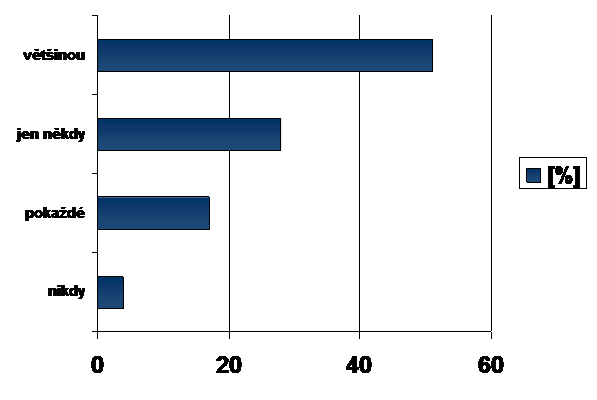
Obr. 1 – Úspěšnost uživatelů při vyhledávání relevantních informací vprostředí internetu
Je však vše problém techniky, nebo jsou problémy ivnaší psychice a nechuti trpělivě hledat? Přizpůsobit se?
OTEVŘENÁ BUDOUCNOST DÁVÁ NAPOVĚDĚT JIŽ DNES
Jistou reakcí na výše uvedené chování uživatelů bylo zavedení federativního vyhledávání (princip přístupu k informacím rozprostřeným ve více zdrojích), ideálně zjednoho vyhledávacího formuláře, což podporuje jednoduchost zadávání dotazů vprůběhu vyhledávacího procesu a oprošťuje uživatele od práce s rozmanitými formuláři u různých zdrojů apod. Ukazuje se, že to je krok správným směrem, ale je žádoucí jít ještě dále. Směrem kfunkcím vyhledávacích nástrojů nové generace, které jsou již dnes testovány a zaváděny do praxe. Patří sem především:
S dalším rozvojem nových technologických přístupů kvyhledávání budeme vbudoucnu čím dál častěji konfrontováni sotázkou co vlastně hledáme? A co po vyhledávacím stroji požadujeme, aby nám předložil jako skutečně relevantní výsledek? Budou to informace, tak jak je vběžné podobě nacházíme vprostředí internetu již nyní anebo to budou znalosti, kdy na položenou otázku vyhledávací stroj vrátí nejpravděpodobnější odpověď či rovnou výpočet?
Budoucí odpovědi na tyto a další otázky je rovněž možno hledat již nyní vpřítomném čase. Krom zástupce klasického webového vyhledávacího stroje se zaměřením především na informační složku, jakým je např. Google, zde existují také zajímavé alternativy vpodobě webových vyhledávacích strojů: PowerSet, Hakia, Cognition či Wolfram Alpha.
Zvláště posledně jmenovaný by se dal označit za typického zástupce kategorie výpočetně-znalostního vyhledávacího stroje, který kombinuje faktické encyklopedické znalosti sinformačními indexy. Například na dotaz o počtu obyvatel vČR Wolfram Alpha vrátí napoprvé požadovanou hodnotu, doplněnou navíc o přehledové grafy s historickým vývojem a nabídne také několik dalších přehledně seřazených znalostních údajů, zatímco při zadání stejného dotazu prostřednictvím Google, je třeba daný údaj nejprve chvíli hledat mezi nabízenými výsledky.
Výpočetně-znalostní vyhledávací stroje však mají před sebou ještě dlouhou vývojovou cestu. Jejich testovací provoz prozatím poukázal především na problém udržitelnosti a aktuálnosti rozsáhlých znalostních databází, přičemž obsáhnout všechny možné kombinace informací pouze na základě analýzy přirozeným jazykem položené otázky, to je věcí prozatím nedosažitelnou. Nicméně znatelný posun ve vývoji těchto modelů vposledních dvou letech dává tušit, že pozice současné světové jedničky mezi vyhledávacími nástroji zase nemusí být tak neochvějná jak se ještě donedávna zdálo – každý nechť zvolí si svou cestu za znalostmi či aktuálními informacemi.
ZÁVĚR
Je samozřejmé, že názory na vyhledávací nástroje nové generace mohou být různé. Jinak se na ně bude dívat informační profesionál, který je ve vyhledávání zběhlý, a jinak běžný uživatel.
Vzásadě můžeme říci, že svýhledem do budoucna nebude vždy bezprostředně nutné pro vyhledávání pokládat dotazy pouze vtextu a taktéž vyhledávače nebudou poskytovat pouze textové odpovědi. Bude-li třeba indexovat např. vůni, bude to možné, avšak poněkud nákladné.
Nezanedbatelná do budoucna bude také otázka ochrany soukromí, kdy se dnes například dají jednoduše najít vazby mezi lidmi, které mohou být publikovány vrámci výsledků vyhledávání.
Obrovský potenciál má také vyhledávání a rozpoznávání dotazů pomocí hlasu, na které si už lidé začínají pomalu zvykat. Nejde jen oto, že nabízí zpravidla rychlejší způsob vlastního vyhledávání, ale může také významně ovlivnit směr vývoje mobilních zařízení a telefonů.
ZDROJE
Aktuální číslo
Odborný vědecký časopis Trilobit | © 2009 - 2026 Fakulta aplikované informatiky UTB ve Zlíně | ISSN 1804-1795