
Pavlech Michal
Ústav informatiky a umělé inteligence
Fakulta aplikované
informatiky, Univerzita Tomáše Bati ve Zlíně
e-mail:pavlech@fai.utb.cz
Abstract
This article deals with MapReduce programming model. This model is aimed at simplifying parallel computations on high number of separated computers, which communicate through network. These computers are not sharing any memory. Article includes brief definition of its inner workings, examples of use and description of some existing implementations. Last part describes proposed adaptation of SOMA algorithm to parallel computing using Hadoop framework.
Abstrakt
Tento článok sa zaoberá programovacím modelom MapReduce. Jedná sa o model zjednodušujúci paralelné výpočty na veľkom množstve samostatných počítačov komunikujúcich cez sieť bez zdieľanej pamäte. Poskytuje stručné vysvetlenie jeho činnosti, príklady použitia a popis niektorých existujúcich implementácií. Ďalej je predložený návrh na úpravu algoritmu SOMA na paralelné výpočty pomocou MapReduce frameworku Hadoop.
Úvod
S rozvojom internetu a nárastom počtu webových stránok rástol počet informácií ktoré musia jednotlivé vyhľadávacie služby spracovávať a indexovať pre budúce použitie. Algoritmy, ktoré tieto informácie spracovávajú sú spravidla jednoduché a nenáročné na výpočet. Avšak množstvo vstupných dát túto úlohu značne komplikuje a výpočty musia byť distribuované na niekoľko stoviek až tísícok paralelne pracujúcich počítačov, aby bolo možné získať výsledok v primeranom časovom rámci. Na tieto úlohy bolo vyvinutých množstvo jednorázových riešení, tie však museli riešiť problémy ako napríklad paralelizácia výpočtov, distribúcia potrebných dát, zlyhania jednotlivých výpočtových jednotiek. Preto sa pôvodne jednoduché programy nabaľovali o stále rozsiahlejšie a zložitejšie rutiny na ošetrenie týchto problémov. Ako unifikovaný spôsob práce s paralelnými výpočtami bol vytvorený programovací model s názvom — MapReduce.
Popis činnosti MapReduce
MapReduce je programovací model vyvinutý a patentovaný spoločnosťou Google. Jeho účelom je spracovanie veľkého množstva dát (rádovo terabyty) na výpočtových clusteroch s vysokou mierou paralelizmu. MapReduce bol inšpirovaný funkciami map a reduce používanými vo funkcionálnych jazykoch, napríklad v jazyku LISP [4].
Volanie funkcie map je distribuované na niekoľko samostatne bežiacich počítačov. Distribúcia je realizovaná pomocou rozdelenia vstupných dát na M častí. Takto rozdelené časti môžu byť spracované paralelne na rôznych strojoch. Volania funkcie Reduce sú distribuované pomocou rozdelenia priestoru kľúčov na R častí, najčastejšie pomocou hashovacej funkcie: hash(kľúč mod R). Rozdeľovacia funkcia, a teda aj počet častí, môžu byť definované používateľom.
Na Obr. 1 je zobrazený celkový priebeh jednej MapReduce úlohy v implementácii firmy Google. Pri volaní MapReduce úlohy prebieha nasledujúci sled činností [3]:
![Text Box: Obr.1: Detaily činnosti Mapreduce [3]](/data/articles/pavlech_files/image001.gif)
Obsluha chýb
Pôvodným určením modelu MapReduce bola činnosť na veľkom množstve počítačov, ktoré sú zostavené z bežne dostupného hardwaru. Preto sa musí priamo pri návrhu frameworku počítať so zlyhaním jednotlivých výpočtových uzlov. Najjednoduchším spôsobom ako prebieha obsluha chýb je opätovná realizácia nedokončenej úlohy. Master periodicky kontroluje stav pracovných uzlov. Ak od niektorého nedostane žiadnu odpoveď je tento uzol označený ako chybný a úloha, ktorú vykonával je pridelená inému voľnému uzlu. Dokonca aj už dokončené úlohy sa musia pri zlyhaní znovu spustiť, pretože prechodné výsledky sú uložené na lokálnych diskoch jednotlivých uzlov. To neplatí pre dokončené redukovacie úlohy, pretože ich výsledky sa spravidla zapisujú na globálny, distribuovaný súborový systém.
Ukážkové príklady
V pôvodnej práci o modeli MapReduce [3] je možné nájsť jednoduché príklady demonštrujúce popisovanú funkčnosť modelu MapReduce. Detailnejšie je popísaný len prvý problém, ostatné príklady sú len spomenuté na ukázanie rozmanitosti riešených úloh.
Základnou uvádzanou úlohou je počítanie slov. Cieľom je vytvoriť program, ktorý spočíta početnosť výskytu jednotlivých slov vo veľkej kolekcií dokumentov. Užívateľ vytvorí funkcie Map a Reduce, ktorých činnosť popisuje nasledujúci pseudo kód:
|
Map(String key, String value): // key: nazov dokumentu // value: obsah dokumentu foreach word w in value: EmitIntermediate(w, "1"); |
Reduce(String key, Iterator values): // key: slovo // values: zoznam počtu výskytov int result = 0; for each v in values: result += ParseInt(v); Emit(AsString(result)); |
Funkcia map emituje každé nájdené slovo spolu s počtom jeho výskytov (v tomto jednoduchom prípade 1 ). Funkcia reduce vytvára výsledný súčet, ktorý počtom výskytov daného vo všetkých dokumentoch. Priebeh celého riešenia toho tu príkladu pomocou MapReduce je na Obr. 2.
Ďalšie úlohy, na ktoré sa MapReduce využívá:
![Text Box:
Obr. 2: Schéma riešenia príkladu počítania slov pomocou MapReduce [11]](/data/articles/pavlech_files/image002.gif)
Voľne dostupné implementácie
Od predstavenia modelu MapReduce v roku 2004 vzniklo niekoľko voľne dostupných implementácií. Ich zameranie, možnosti, podporované programovacie jazyky, architektúry a hardwarové platformy sa značne líšia. Nejedná sa o kompletný prehľad všetkých existujúcich riešení, ale len o výber najzaujímavejších zástupcov:
Implementácia algoritmu SOMA v prostredí MapReduce
Algoritmus SOMA
SOMA je pomerne nový algoritmus určený na optimalizáciu mnohorozmerných funkcií. Samotný názov je skratkou zo: „Samo organizujúci sa migračný algoritmus“. Základné princípy činnosti algoritmu sú založené na správaní sa inteligentných jedincov, ktorí kooperujú na riešení spoločnej úlohy. Vlastnosť samoorganizácie vyplýva z faktu, že sa jedinci pri hľadaní najlepšieho výsledku navzájom ovplyvňujú. Algoritmus je možné zaradiť do skupiny tzv. evolučných algoritmov, aj keď v tomto prípade nedochádza k tvorbe nových potomkov, len k ich migrácii. Z toho dôvodu sa jedna iterácia algoritmu nazýva migračné kolo.
Rovnako ako v prípade iných evolučných algoritmov je tvorba nových jedincov realizovaná pomocou mutácie a kríženia.
Mutácia je premenovaná na perturbanciu. Dôvodom je skutočnosť, že mutáciou je spôsob, akým sa pohybujú jedinci priestorom možných riešení. Pre každého jedinca sa pred každým krokom generuje perturbačný vektor, ktorý má rovnaký rozmer ako jedinci v populácii. Následne sú generované náhodné čísla a porovnávané s vopred zadaným parametrom PRT, ak je náhodné číslo menšie je na príslušnú pozíciu v perturbačnom vektore priradená hodnota 1, v ostatných prípadoch hodnota 0.
Kríženie predstavuje tvorbu nového potomstva, v tomto prípade sa jedná o pohyb jedincov po diskrétnych krokoch v priestore pomocou dvoch už existujúcich jedincov (rodičov). Počas pohybu si každý jedinec pamätá súradnice, kde našiel najlepšie riešenie, toto riešenie postupuje do ďalšieho migračného kola. Pohyb jedincov sa riadi podľa rovnice:
Kde ![]() je pozícia
aktívneho jedinca na počiatku,
je pozícia
aktívneho jedinca na počiatku,
![]() pozícia jedinca s
najlepšou hodnotou účelovej funkcie (vedúci jedinec, leader),
pozícia jedinca s
najlepšou hodnotou účelovej funkcie (vedúci jedinec, leader),
![]() perturbačný vektor
a t je hodnota kroku z intervalu [0, PathLength].
perturbačný vektor
a t je hodnota kroku z intervalu [0, PathLength].
Perturbačný vektor ovplyvňuje pohyb jedinca tak, že ak má všetky prvky rovné 1, tak sa aktívny jedinec pohybuje priamo k vedúcemu jedincovi. Ak je však niektorý prvok rovný 0, potom sa daná súradnica nemení a cesta priestorom je odklonená z priameho smeru. To zaručuje, že je prehľadávaná väčšia časť priestoru.
Detailnejšie informácie o algoritme SOMA je možné dohľadať napríklad v [12].
![Text Box: Obr. 3: Princíp činnosti SOMA pred migráciou, po migrácii [12]](/data/articles/pavlech_files/image007.gif)
Úprava na model MapReduce
Algoritmus SOMA je už vo svojej podstate veľmi vhodný na úpravu na paralelnú architektúru. Na implementáciu bol zvolený MapReduce framework Hadoop [8] hlavne pre veľké množstvo existujúcich publikácií [1] a dodatočným nástrojom poskytovaným v rámci frameworku (napr. distribuovaný súborový systém, distributed cache, monitorovacie nástroje).
MapReduce je využitý na zvýšenie výkonu pri „pohybe“, teda pri tvorbe nových jedincov.. Hľadanie najlepšej hodnoty účelovej funkcie prebieha sériovo, pretože sa jedná o jednoduchú úlohu porovnávania už vypočítaných hodnôt. Distribuovaný spôsob vyhľadávania by nepriniesol žiadne zlepšenie, práve naopak.
Každé volanie mapovacej funkcie predstavuje pohyb jedného jedinca z populácie v priestore. Aby bol tento pohyb možný, je nutné poznať pozíciu najlepšieho jedinca. Preto má každý výpočtový uzol uloženú jeho hodnoty v danom migračnom kole. Počet jedincov, ktorý budú spracovaný na jednom mapovacom uzle závisí na požadovanej veľkosti populácie a množstva mapovacích uzlov, ktoré má algoritmus k dispozícii. Nie je možné dopredu predpokladať koľko jedincov bude ktorý uzol spracovávať, pretože tieto množstvá sú ovplyvňované množstvom faktorov (napr. vyťaženosť, výkon, sieťové pripojenie, chybovosť jednotlivých uzlov), ktoré nie je možné vopred presne poznať.
Redukovacia funkcia slúži len zapísanie jednotlivých jedincov na distribuovaný súborový systém. Súčasť implementácie MapReduce vo frameworku Hadoop je funkcia „distributed cache“, ktorá je určená na distribúciu zdieľaných súborov. V tomto prípade je použitá na distribúciu najlepšieho jedinca k jednotlivým pracovným uzlom.
Pre urýchlenie inicializácie je vytváranie počiatočnej populácia taktiež vykonávané paralelne, ako súbor Map funkcií. Každá Map funkcia inicializuje pri svojom volaní jedného jedinca na náhodné hodnoty v ich povolenom rozsahu a následne spočíta hodnotu účelovej funkcie. Takto vytvorený jedinci sú uložený do dsitribuovaného súborového systému, odkiaľ k nim majú prístup ostatné fázy programu.
Celá populácia je uložená na distribuovanom súborovom systéme, je teda spätne možné dohľadať priebeh evolúcie, alebo znovu naštartovať evolúciu s už existujúcou populáciou.
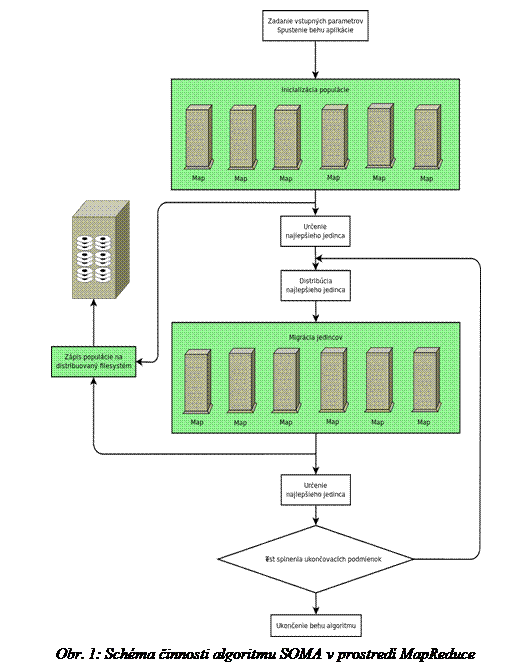
Činnosť algoritmu je schematicky zobrazená na Obr. 4. Na tejto schéme sú časti, ktoré sú vykonávané paralelne na viacerých výpočtových uzlov zakreslené so zeleným pozadím.
Navrhovaná úprava algoritmu SOMA by priniesť zrýchlenie výpočtu pri optimalizácii problémov s vysokou mierou zložitosti účelovej funkcie, pretože profituje z paralelného ohodnotenia viacerých jedincov zároveň. Nie je však vhodná na optimalizáciu problémov, kde vyhodnocovanie účelovej funkcie je pomerne jednoduché. Framework Hadoop totiž spotrebuje určitý čas na komunikáciu medzi jednotlivými uzlami, inicializáciu, distribúciu a zapisovanie výsledkov. Ak by bol čas potrebný na výpočet účelovej funkcie rádovo menší ako je čas potrebný na réžiu frameworku, strácala by sa výhoda paralelizácie výpočtov a paradoxne by dochádzalo k predlžovaniu výpočtu. Minimálny čas vykonávania účelovej funkcie nie je možné vopred odhadnúť, je potrebné vykonať testy na konkrétnom type hardwaru.
 |
Záver
MapReduce hneď po svojom predstavení v roku 2004 vzbudil záujem odbornej verejnosti. Dôkazom tohto záujmu je množstvo existujúcich implementácií, ktoré využívajú popredné firmy z IT priemyslu pre svoje potreby. Medzi najznámejšie nasadenia patrí Amazon [13], Facebook, Myspace, Nokia [7], Google, IBM, Sony a iné, ako aj výskumné projekty využívajúce MapReduce na analýzu dát [5], [6]. Podstata úspechu spočíva hlavne v jednoduchosti s akou je možné vytvárať distribuované aplikácie. Jediný požiadavok na užívateľa (samozrejme okrem potrebného hardwaru) je implementácia dvoch funkcií (Map a Reduce) a úprava riešenia problému na tento programovací model. Táto úprava spravidla nie je nijako drastická a je blízka ľudskému spôsobu myslenia, popritom stále schopná priniesť požadované výsledky. Samozrejme nie každá úloha je vhodná na implementáciu pomocou modelu MapReduce.
Veľkým prínosom programom vytvorených pomocou MapReduce frameworkov je možnosť jednoduchého využitia hardwarovej infraštruktúry od poskytovateľov cloud computing služieb (napr. Amazon Elastic MapReduce [13]). Využitím týchto služieb môžu užívatelia obmedziť prostriedky na nákup hardwaru a jeho správu a platiť len za čas potrebný na výpočet aktuálneho problému.
Úprava algoritmu SOMA umožňuje jeho beh v prostredí frameworku Hadoop. Distribuovaný spôsob výpočtov by mal priniesť zefektívnenie riešenia zložitých problémov. Bohužiaľ v čase vzniku tohto článku práve prebiehali simulácie navrhovaného riešenia, preto zatiaľ nie je možné v tejto dobe podať relevantné výsledky. Tie budú dostupné až po skončení simulácií a vyhodnotení ich úspešnosti..
Navrhovaný spôsob riešenia nevyužíva algoritmus MapReduce kompletne, pretože vynecháva Reduce fázu. Súčasný výskum sa bude zameriavať na vývoj evolučných algoritmov, ktoré budú využívať programovací model MapReduce ešte efektívnejšie.
Referencie
Aktuální číslo
Odborný vědecký časopis Trilobit | © 2009 - 2026 Fakulta aplikované informatiky UTB ve Zlíně | ISSN 1804-1795