
Ing. Iveta Žouželková, Ing. Radek Vala
Department of Computer and Communication Systems
Department of Informatics and Artifical Intelligence
Tomas Bata University in Zlin
Faculty of Applied Informatics
nám. T. G. Masaryka 5555, 760 01 Zlín, Czech Republic
E-mail: zouzelkova@fai.utb.cz, vala@fai.utb.cz
Abstrakt
Příspěvek se zabývá možnostmi ukládání polí vnejběžnějších databázových systémech (DBMS). Datový typ pole, jež je součástí většiny programovacích jazyků a je velmi vhodný například pro zpracování diskrétních hodnot výstupu měření signálů či časových řad. Vývojáři mají dnes poměrně velký výběr zrůzných databázových technologií a správná volba databáze a datového typu pro ukládání polí nemusí být úplně zřejmá. Včlánku jsou popsány možnosti ukládání polí jak vopen-source DBMS (MySQL, PostgreSQL), tak vkomerčním MS SQL. Byly testovány tyto základní přístupy – ukládání pole přímo do datové struktury pole (z testovaných dostupné pouze v PostgreSQL), ukládání pole jako řetězec (či serializovaný řetězec) do jediného sloupce v tabulce, ukládání hodnot pole do samostatných sloupců vtabulce a ukládání hodnot pole do řádků. V závěru jsou pak provedené testy zhodnoceny a diskutovány jejich výhody a nevýhody zhlediska konkrétní aplikace.
Abstract
This study is designed to suggest the possibilities of storing arrays in the most common Database management systems (DBMS). An array data type is a common part of most programming languages and is very suitable for example for processing discrete values of signal and time series measure. The offer of DBMS is very large in these days and the best solution to store arrays may not be obvious. This article discuss the possibilities of storing arrays in open-source DBMS (MySQL, PostgreSQL), even in commercial MS SQL. These basic approaches were tested – storing an array in an appropriate array data type (available only in PostgreSQL), storing an array as a string (or serialized string), storing array values to separate columns in a table and storing values into rows. Performed tests are evaluated and discussed in conclusion and also pros and cons of each approach are discussed in the frame of specific application.
Introduction
An increasing interest in data storage brought a question of a useful database tool for saving arrays of data. Time series, discrete signals values, measured data and other data structures should be stored as arrays. A wide range of database management systems (DBMS) is offered, but not all of them support the appropriate data type. Developers could be confused by this wide choice of relational, object – oriented, object-relational and other systems [1].
Several researchers have run time response tests of databases such as MySQL, MS SQL, PostgreSQL and Other DBMS, in order to investigate suitability of these systems for various applications. The comparison of these results is impossible, because they were gained on different hardware configurations and under changed conditions. It is also hard to discover an objective confrontation of the most common DBMS, especially their possibilities of storing arrays. This work deals with performance tests of the most common, mostly used, commercial as well as open-source DBMS: relational MySQL, MS SQL Server 2008 and object-relational PostgreSQL.
Different Approaches to Saving Arrays
Inserting data fields into a database is not trivial. The most of database systems do not offer attributes of an array data type. In these cases a convenient substitution should be found. The only DBMS allowing columns of a table to be defined as an array is PostgreSQL. Other systems are able to save a field as a number of attributes (each attribute for each value) or as a string. This study focuses on saving arrays of numeric data.
a) An array data type
As mentioned before, an array data type is not commonly implemented in several DBMS. On the other hand, PostgreSQL provides attributes of a table to be defined as variable-length multidimensional arrays of any built-in or user-defined base type. The syntax for creating a table allows the specification of the exact size of arrays. However, the current implementation does not enforce the array limits – the behavior is the same as for arrays of unspecified length. Actually, the current implementation does not enforce the declared number of dimensions either. Arrays of a particular element type are all considered to be of the same type, regardless of size or number of dimensions. So, declaring number of dimensions or sizes while creating table is simply documentation, it does not affect run-time behavior. [2] The fig. 1 shows the syntax of the CREATE TABLE query including one-dimensional array array1dim of type integer and two-dimensional array array2dim of text.

Fig. 1: Example of creating a table with an unspecified array
This approach has its advantages and disadvantages. In other words, users can create an array even if they are not able to determine the final length. In fact, each record can have a different length and dimensions of the array as illustrates fig. 2 . On the other hand, the knowledge of this parameter during a design process does not influence the performance.

Fig. 2: Example of a different length and dimensions in the table measurement
b) Storing each value into a separated column
Storing values into predefined attributes of numeric data types appeared to be the next possibility. As can be seen in fig. 3 the size of the array should be known for the database design. This requirement can limit saving for example time series and signals with unknown number of values. Despite this fact, each signal (including time series) can be described by an array of coefficients which allow signal reconstruction. For example the discrete wavelet transform outputs 16 transform coefficients, which can characterize every signal very precisely.

Fig. 3: Storing values into separated columns
The advantages of this solution can be found in the speed of response. INSERT, UPDATE and SELECT queries were supposed to be fast. Data could be effectively selected by complex restrictions. This approach is easily applicable to different platforms.
c) Storing an array as a string
The last option offered by all systems is the usage of a string attribute. The values can be saved into a varchar or text data type. In this case the requirement of length knowledge is fundamental, because the amount of data inserted into these data types is restricted. This solution can also bring problems with comparing the particular coefficients and searching for data in the defined range of values. Selecting data with restrictions is shortened to full text search.
d) Storing a serialized array
Another possibility is storing an array data structure as a serialized value. All major programming languages offer serialization. It is a two way process of converting a data structure or an object into a usable format for storing, usually some kind of string value. Serialized string can be deserialized without a loss of the data structure.
Serialized value of an array can be stored into the DB as a string. Its length depends on the length of the original array. Therefore, possible length of an array should be already known during designing a database structure to selecting an appropriate data type of a database column.
Storing array values as a serialized string has a significant disadvantage stemming from stored format of serialized string. An original array is stored in a database like a common string value and it is not possible to search effectively. Moreover, ordering original array keys by values on the side of a database engine can be a problem. Only a full text search on this column can be used, but it must be adapted to the format of the serialized string according to the selected programming language. An example of the usage reveals fig. 4.

Fig. 4 : Serialization in PHP
e) Storing values into rows
An array data can be also stored into rows. In this case each value is saved as a separate record into a table. This approach is suitable for the types of application, where the dimensions of the array are not known. Moreover, records should include an attribute containing the information about the dimension level the value corresponds to. The main advantage of this solution is availability on almost every DBMS.
Testing Methods and Tested DBMS
In order to investigate performance of the previously mentioned data types a time response test was designed. On the presumption that the results should be comparable, all approaches were tested on the same machine with the same hardware configuration (Intel(R) Core(TM)2 Duo CPU P9400 2,4 GHz, 4GB RAM, WIN7 32bit). For MySQL tests Wamp Server 2.0 with Apache 2.2.11, PHP 5.3.0 and MySQL 5.1.36 were installed, for MSSQL tests MS SQL Server 2008 and for Postgre tests PostgreSQL 8.2 were chosen. All tests were processed through PHP script, using ADOdb library and time was measured using the PHP function microtime(). ADOdb is a database abstraction library for PHP which allows developers to write applications in a consistent way and change the database without rewriting every call to it in the application [3].

Fig 5: Tested data types on chosen platforms
Fig. 5 shows the mentioned DMBS and the tested data types. As declared before PostgreSQL has implemented an array data type. The tests focused on the performance comparison of separated numeric attributes ( var. b)) and the array data type. The text usage (var. c) was not tested in this DBMS, because this solution was schemed up as a compensation of missing array type in other DBMS.
MySQL offers several storage engines – for this work the most common MyISAM and InnoDB were chosen. MyISAM is generally known as a default MySQL storage engine. It is based on the older ISAM code but has many useful extensions. It contains many functions programmed during years of usage. MyISAM is widely used in web applications as it has traditionally been perceived as faster than InnoDB in situations where most DB access is reads. On the other hand, InnoDB provides transactions with data consistency check. These and other security mechanisms can be more demanding and cause worse results. [4,5,6] Separated attributes (var. b) and string values (var. c) were used in both engines.
MS SQL server 2008 supports different data types, but an array data type should be saved in a different way. The same data types as in the MySQL case were used. Only the latest release (MS SQL Server 2008 R2 Express edition) was employed, because the main aim of this work was not to compare the impact of different versions on the watched performance.
From the perspective of the database performance serialized data behave the same structure as a string. Restrictions in a where clause can be applied only as a full text search. This discovery brought simplification into the test.
In the next step, the attention should be paid to the tested queries. First of all the INSERT statement entered 100, 1000 and 10,000 records and time of the processing was measured. The SELECT query with 16 restrictions was applied on 100,000 rows. Each step was ten times repeated and the results were averaged out.
Results
a) The INSERT query
The comparison of the results of INSERT query can be seen in fig 6, fig 7 and fig8. The first graph reveals processing time of different number of inserted rows. According to this study, MyISAM tended to perform better than other tested engines while saving 16 attributes of numeric data types. On the other hand saving strings seemed to be the fastest in the case of MS SQL Server. Surprisingly, saving the array data type in PostgreSQL was slower than saving text in MS SQL Server.
Storing 16 attributes into rows caused an increase of the tested records. Unlike the previous cases, the performance was tested on 1,600 16,000 and 160,000 rows, because each array occupied 16 rows . The result showed that MyISAM performed best again. In contrast, the increase of the rows caused problems with saving records in InnoDB. The testing server was not able to manage the demand. Consequently, InnoDB was not tested for var. e). Furthermore InnoDB appeared to be the slowest database engine, but this outcome was expected.
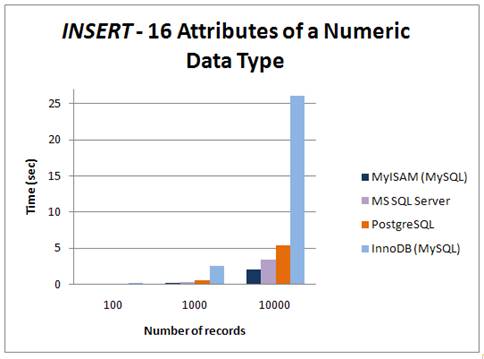
Fig 6: INSERT – 16 attributes of a numeric data type on different platforms
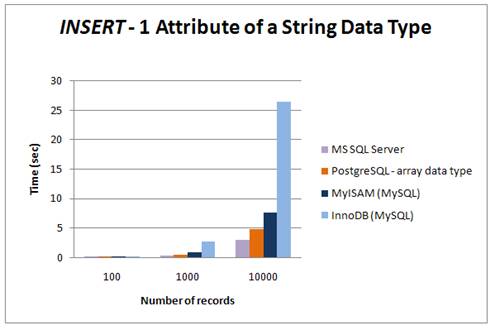
Fig 7: INSERT – 1 attribute of a string data type on different platforms
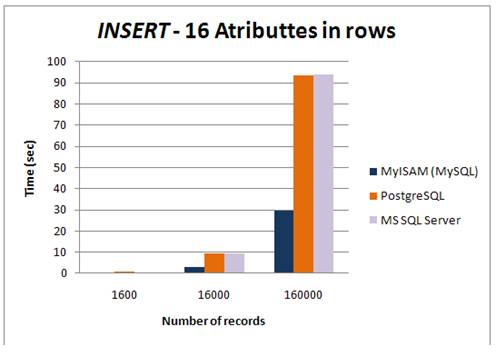
Fig 8: INSERT – 16 attributes of a numeric data type saved in rows on different platforms
b) The SELECT query
On the data available the SELECT query resulted very similarly in the case of numeric attributes. Fig 9 shows that MyISAM reached the lowest time response. On the other hand, MS SQL Server is possibly the slowest. The results revealed in fig. 10 present that using the array data type is faster than the full text search in strings. This result was expected. Testing queries are presented in fig.11.
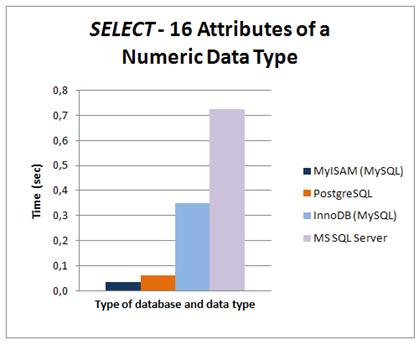
Fig 9: SELECT – 16 attributes of a numeric data type on different platforms
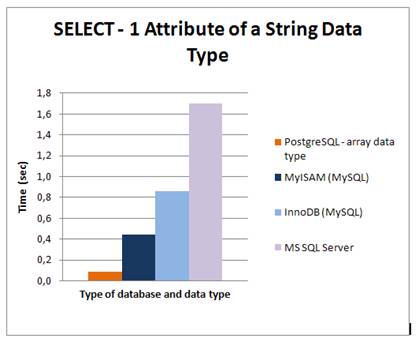
Fig 10: SELECT – 1 attribute of a string data type on different platforms
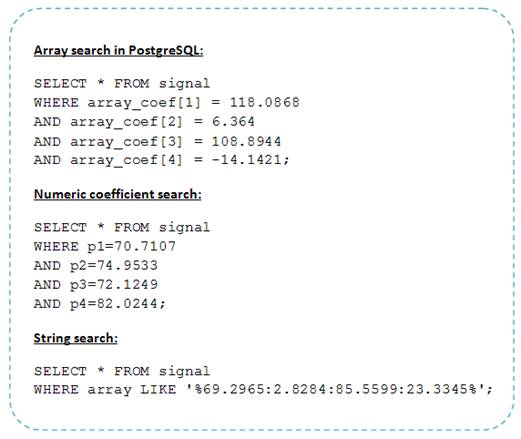
Fig 11: SELECT queries – 4 restrictions examples
Fig. 12 opens a discussion about the usage of saving arrays into rows. The first problem was the definition of the SELECT query. In the case of the array saved in 16 records, the query should contain aggregation for intersection of restrictions (fig.13) that can negatively affect the results. The test showed that MyISAM is faster than other systems. On the other hand, this approach is the slowest and least comfortable for developers.
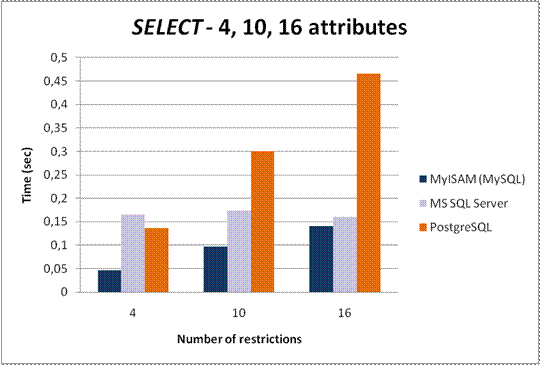
Fig 12: SELECT – 4, 10 and 16 attributes of a string data type saved in rows on different platforms

Fig 13: SELECT query for “in rows” search – 4 restrictions example
Confrontation of the three fastest engines in each approach (fig. 14) shows, that selecting data in fields saved as separated attributes can be faster than using an array data type. Saving arrays in rows is not very useful.
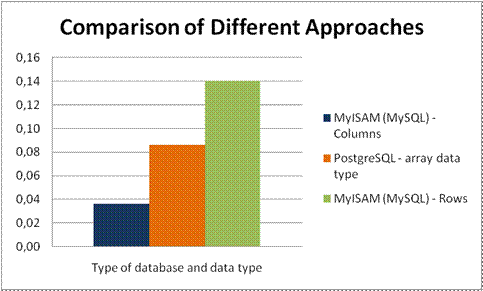
Fig 14: SELECT – Comparison of the MyISAM selecting in 16 attributes, PostgreSQL searching in an array attribute and MyISAM selecting data in 16 rows.
Conclusion
The main purpose of this survey was to offer different approaches of saving arrays into databases. The chosen variants were tested and compared. The results showed that generally saving data in a string data type is more demanding than inserting records into separated numeric attributes. Also selecting records on the base of 16 attributes was faster than a full text search. A data type array offered by PostgreSQL performed also satisfactorily. Saving arrays in rows appeared to be very demanding (especially the INSERT query) and uncomfortable for future use of the data.
On the other hand, each way of saving information such as signal measurements, time series and other fields of values has its pros and cons. Each approach is suitable for a different field of application. Previously known size of the array could lead to usage of a different attribute for each value, except very long arrays. In these cases this approach would be smart and comfortable for developers. If the dimension of the array is not known, usage of a string attribute, arrays or saving into rows could be possible, but not always appropriate. Another way of storing arrays can be seen in the XML technology. This study has concentrated on DBMS possibilities and XML can be a suitable basis for future analysis.
According to this study, the best solution seems to be the usage of an array data type, if it is possible. Other variants are somehow limited. It should be noted, that this study is based on the INSERT and SELECT queries and embedded procedures can bring different results.
Acknowledgements
This survey was financed by Internal Grant Agency of Tomas Bata University in Zlin, Faculty of Applied Informatics IGA/49/FAI/10/D, No. SV30111049020.
References:
[1] VAUGHN, William. Choosing the "Right" DBMS Engine. Internet.com [online].
October 22, 2007 <http://www.developer.com/db/article.php/3706476/Choosing-the-Right-DBMS-Engine.htm>.
[2] PostgreSQL 8.2 Documentation [online]. 2005 PostgreSQL. <http://www.postgresql.org/docs/8.2/interactive/arrays.html>.
[3] ADOdb. In Wikipedia : the free encyclopedia [online]. St. Petersburg
(Florida) : Wikipedia Foundation, 21 March 2005, last modified on 26 August 2010
[cit. 2010-10-20]. <http://en.wikipedia.org/wiki/ADOdb>.
[4] NEWTON, Narayan. Home Tag1 Consulting, Inc. [online]. 2008 MySQL Engines:
MyISAM vs. InnoDB. <http://tag1consulting.com/MySQL_Engines_MyISAM_vs_InnoDB>.
[5] The MyISAM Storage Engine. MySQL [online]. 2011, [cit. 2011-03-30].
<http://dev.mysql.com/doc/refman/5.0/en/myisam-storage-engine.html>.
[6] The InnoDB Storage Engine. MySQL [online]. 2011, [cit. 2011-03-30].
<http://dev.mysql.com/doc/refman/5.0/en/innodb-storage-engine.html>.
Aktuální číslo
Odborný vědecký časopis Trilobit | © 2009 - 2026 Fakulta aplikované informatiky UTB ve Zlíně | ISSN 1804-1795