
Michal Šmiraus
Thomas Bata University in Zlín, Faculty of Applied Informatics
Nad Stráněmi 4511, Zlín, 760 01
E-mail: smiraus@fai.utb.cz
Abstract
Web of today is a huge data collection of various documents which is in fact strongly human oriented and designed for human consumption, but not so suitable for automatic information processing by software agents that cannot understand it. Semantic Web represents possible way to change this situation and is supposed to be an extension of the World-Wide Web where the meaning of data is available and processable by computers. However, the current recommended Semantic Web languages, RDF and RDFS, are not built on top of the current World-Wide Web. In order to describe the semantics of the World-Wide Web, the Semantic Web must be based on XML, the data format of the World-Wide Web. This paper briefly presents the options of the basic semantic language RDF and a possible approach to creating and using ontology mapping tool TopBraid with advanced semantic language SPARQL.
Keywords: semantic web, ontology, wordnet
1 INTRODUCTION
Ontology is a formal description of a domain of discourse, intended for sharing among different applications, and expressed in a language that can be used for reasoning (Shvaiko and Euzenat, 2005). A formal description refers to an abstract model of some phenomenon in the world that identifies the relevant concepts of that phenomenon. “Expressed” specification means that the type of concepts used and the constraints on their use are explicitly defined. “Formal” refers to the fact that the ontology should be machine understandable and “sharing” reflects the notion that ontology captures consensual knowledge, which is not restricted to some individual but accepted by a group. Large ontology like WordNet provide a thesaurus for over 100,000 terms explained in natural language.
In ontology user can organize information into taxonomies of concepts and describe relationships between them, each with their attributes. More recently, the notion of ontology has also become widespread in fields such as intelligent information integration, cooperative information systems, information retrieval, electronic commerce and knowledge management.
The World Wide Web was originally built for human consumption, and although everything on it is machine-readable, but significant difference is that data is not machine-understandable. In order to make data on the Web be machine-understandable, we can use metadata to describe the data contained on the Web. Metadata represents "data about data" (e.g. as a library catalog is metadata, since it describes publications) or specifically in the context of this specification "data describing Web resources" (Sean, 2001). Resource Description Framework (RDF) is a foundation for processing metadata; it provides interoperability between applications that exchange machine-understandable information on the Web. RDF emphasizes facilities to enable automated processing of Web resources.
2 MODEL THEORY OF THE ONTOLOGY MAPPING
Ontology mapping is the process of taking two independently created ontologies or schemes and determining commonalities relations between them. This common ontology could be used as the primary datasource for external applications to make queries on.
In the core, the Semantic Web exploits knowledge representation theories based on logic. A fundamental requirement is to express rich taxonomic hierarchies enabling effective knowledge organization and reasoning. The simply reason why ontology becomes crucial in future web technology is because they provide a shared and common understanding of some domain that can be communicated among people and application systems. Ontology may use different vocabularies, different design methodologies, might overlap but not coincide. While manually semantic mapping might be possible for small examples, it becomes heavily feasible and time consuming on the Web-scale – large number of ontologies, and large-sized ontologies (Staab, 2006).
But there definitely will be multiple ontologies within a same domain. This is inevitable considering the distributed and autonomous nature of development of web content. Semantic
Mappings are essential to realize the full potential of the Semantic Web vision and allow information processing across ontologies.
Sources of information that can be leveraged to learn semantic mappings are for example data instances which are available from the web content and will be marked up with ontologies that can be used to learn mappings. There might be constraints and heuristics on the mapping – ones that are available from the structure and relationships in the ontologies and from our prior knowledge of the domain of the ontologies. There are many heuristics that might be able to use different types of such information and we need a single framework that will put them all together.
There are 3 approaches to semantic mapping described below:

Fig. 1: Basic scheme of semantic mapping
As you can see on Fig. 1 there is a high-level overview of semantic mapping. Two taxonomies are given and it is desired to obtain mappings between them. In particular for each concept in the left is desirable to map it to the most similar concept on the right and most similar is something that is application specific, and depends on the purpose of our mappings.
The first step in a mapping process is to define a meaning for similarity. The next step is to compute the similarity with concepts in the other taxonomy as defined by measure. The best mapping might be chosen in a straightforward way by picking the one with the highest similarity value. However before confirming the mapping it is necessary to check if the mapping satisfies different constraints that might be relevant to provided context – possibly altering and fixing the mapping. After examine all components of the system is it possible to put them altogether. It starts out with two sample taxonomies. Estimate the joint probability distribution between pairs of concepts using Multi-strategy learner on the data instances. The Similarity matrix is computed given some definition of similarity. Relaxation labeling is used to incorporate the effects of multiple generic and domain specific constraints. The result is a pair of mappings. This is whole GLUE system described on Fig. 2.
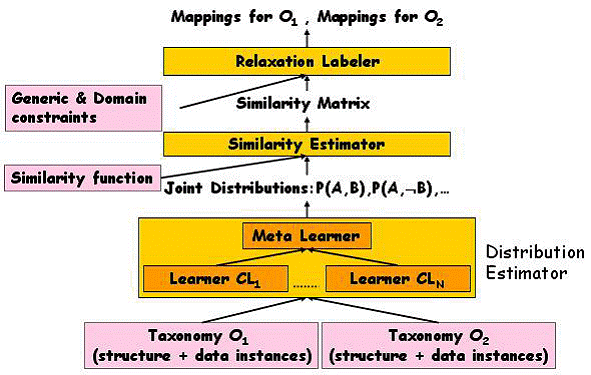
Fig. 2: System architecture of ontology mapping
In this merge, nodes are one of two kinds. One kind of node corresponds to text or value nodes from XML or literal nodes from RDF. These nodes are given labels that are their text or their typed value, as appropriate. The other kind of node corresponds to element or attributes nodes from XML or non-literal nodes or edge labels from RDF. These nodes are given two optional labels, one of which is the RDF identifier and the other of which contains the element or attribute names from XML or the rdf:type(s) or edge label from RDF. Two of these nodes in a graph cannot have the same RDF identifier. To handle the edge ordering of XML, our data models partially order the outgoing edges from each node. A final reconciliation is the difference in naming conventions between XML and RDF which will be ready to go with qualified names, abandoning direct use of URIs (Boley, 2001).
The only change here would be that the meaning provided by XML and XML Schema would end up being the Semantic Web meaning of XML documents, instead of being supplanted by the RDF meaning. The situation is somewhat different from the RDF and RDFS side. RDF is reduced from the main language of the Semantic Web to an extension of XML that really only provides the identifiers (rdf:ID) that tie the XML data model nodes together to make a graph. RDFS is completely gone, being replaced by own as-yet-unspecified Semantic Web Ontology Language, SWOL. SWOL would roughly fill the same role as currently filled by DAML+OIL, but would have a much closer relationship to XML and XML Schema. This SWOL document fragment contains the definition of a class, named Organization. Elements of this class, organizations, have a name, in the form of a string. Elements of the class also can have purchases, each of which must belong to the PurchaseOrderType.
<swol:class name="Organization" defined="no">
<swol:exists>
<swol:class name="name"/>
<swol:class name="xsd:String"/>
</swol:exists>
<swol:all>
<swol:class name="purchase"/>
<swol:class name="PurchaseOrderType"/>
</swol:all>
</swol:class>
Imagine a SWOL document as a collection of several definitions of this sort, each with a name. There are actually many possibilities for SWOL, just as there are many description logics, varying in expressive power from frame-like formalisms up to very powerful ontology-definition formalisms.
This way of giving meaning to documents (usually referred to as collections of statements) is called model theory. It is a formal semantic theory that relates expressions to interpretations.
The name 'model theory' arises from the usage, traditional in logical semantics, in which a satisfying interpretation is called a "model".
The meaning of a document is different in Data Model and in model theory. In data models, the meaning of a document is a single a single data model, which corresponds to the portion of the world being considered. In model theory the meaning of a document is a collection of interpretations. Each of these interpretations corresponds to one of possible ways the world could be, given the information under consideration.
3 COMPOSING ONTOLOGY MAPPING WITH SPARQL CONSTRUCT
According to described model theory of ontology mapping few very promising experiments with using SPARQL were performed. SPARQL (actual version 1.1 from March 2013) is best known as the upcoming W3C standard query language for RDF which allow to pull values from structured and semi-structured data, explore data by querying unknown relationships and perform complex joins of disparate databases in a single, simple query.
Beside its SELECT command, SPARQL also defines a CONSTRUCT keyword. The input of a CONSTRUCT query is a WHERE clause describing a pattern in a source model, including variable definitions. The output is an RDF graph that inserts all matching variable bindings into a target graph template.
Fig. 3 shows an example screenshot from TopBraid Composer's (www.topquadrant.com) new SPARQL visualization. As you can see a SPARQL query is used to convert instances of a source:Person class into target:Person. To make this example more interesting, the string values of source:car are converted into instances of a class target:Car which is shown on Fig. 3:
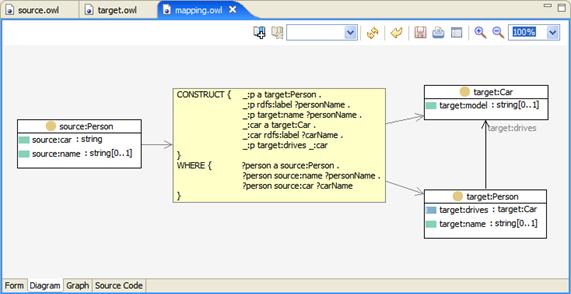
Fig. 3: SPARQL TopBraid Composer visualization
For example, if you have a set of source instances Bob and Alice
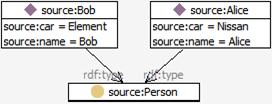
Fig. 4: Setting up of source instances
then the output is a new subgraph in the target model, but with the cars as objects instead of strings:
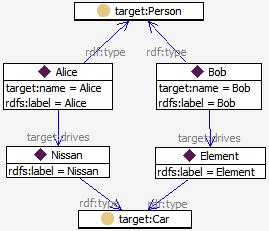
Fig. 5: Output subgraph with a target model
The trick is that CONSTRUCT generates new triples, and these triples can be treated as "inferences" and added to the target model. TopBraid's SPARQL window displays what happens under the hood. The screenshot on Fig. 6 actually shows a different version of the query from above:
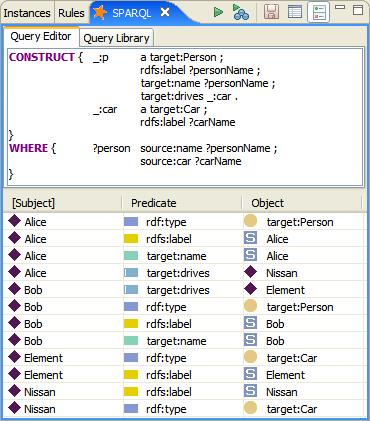
Fig. 6: Mapped ontology with SPARQL Construct
As a query language, SPARQL is "data-oriented" in that it only queries the information held in the models; there is no inference in the query language itself. Of course, the Jena model may be 'smart' in that it provides the impression that certain triples exist by creating them on-demand, including ontology reasoning. SPARQL does not do anything other than take the description of what the application wants, in the form of a query, and returns that information, in the form of a set of bindings or an RDF graph (Feigenbaum, 2009).
The background of SPARQL is expanding every year and there is the large number of tools that support it which may assume that in the near future most of the Semantic Web developers will know SPARQL well and therefore nobody need to learn any other "mapping ontology". Also, SPARQL is supported by optimized query engines, and SPARQL is fairly expressive with regards to query filters etc.
4 CONCLUSION
In spite of 10 years of intensive researches and developments the Semantic Web is actually still mostly a future concept. It is caused by many reasons. Poor theoretical foundation and in the absence of good news and evaluation results make people and especially computer experts more and more pessimistic. Not all parts of the Semantic Web are developed yet. May be the most important parts like agent, trust and retrieval techniques are developed very poor that is strongly restricted for the real usability. Technological base do not allow using Semantic Web in good way. Technological base means the current level of hardware and software that cannot support all Semantic Web features.
Software as well as hardware does not allow to easy develop an application and documents that brakes the mass Semantic Web’s growing. People have no resolution to change the Web and to spend a lot of money. People are very careful after all IT crises with all new technologies which needs a lot of money. It is mostly a psychological problem, but maybe it is the most important problem in the case of making the Semantic Web really a global scale system.
But wide using of the XML created a good foundation for Semantic Web together with already developed software tools for creation Semantic Web application and documents (even poor) allow to reduce the cost of the SW building. In the near future it will be possible to go beyond the keyword searches. Queries can be answered by gathering information from multiple web-pages which is something that is not possible on the Google of today (Bizer, 2009).
That is a good reason to put up money right now. Active position of Scientific Community made people believe in Semantic Web. Right now the problem of the Semantic Web is not a technology but philosophy of the future web existing. People trust the technology, but people believe the philosophy. Technology gives the answer, philosophy teaches to find the answer – maybe in the near future.
References
Aktuální číslo
Odborný vědecký časopis Trilobit | © 2009 - 2026 Fakulta aplikované informatiky UTB ve Zlíně | ISSN 1804-1795