
Ing. Aleš Troszok, Ph.D.
Ostravská univerzita v Ostravě,
Pedagogická fakulta
Katedra informačních a
komunikačních technologií
Fráni Šrámka 3
709 00
Ostrava – Mariánské Hory
ales.tros@seznam.cz
Abstrakt
Informační a komunikační technologie nabízejí stále nové a nové možnosti a tak jako ivjiných oborech, tak i ve vzdělávání je stále větší snaha o využití jejich potenciálu. Moderní informační a komunikační technologie, lze vzhledem kmožnostem, které poskytují, spatřovat vrůzných formách a etapách procesu učení, kde plní své stanovené funkce. Mezi tyto funkce patří i analyticko-vyhodnocovací či diagnostická funkce, které jsou v této práci realizovány prostřednictvím metod data miningu.
Kličová slova
Educational data mining, shluková analýza, analýza hlavních komponent, korelační matice.
Abstract
Information and communication technologies offer new and new opportunities. As well as in other fields so also in education is a growing effort to exploit their potential. Modern information and communication technologies, due to the possibilities they provide can be seen in various forms and stages of the learning process, where it performs its designated functions. These features include the analytical, evaluation and diagnostic functions that are implemented in this work through the methods of data mining.
Key words
Educational data mining, cluster analysis, principal component analysis, correlation matrix.
ÚvodTato práce aplikuje metody z oblasti informačních akomunikačních technologií při zpracování dat získaných ve vzdělávání či vkontextu vzdělávání. V realizovaném výzkumu byly po výpočtu základních statistických charakteristik datového souboru použity metody dobývání znalostí zdat – data minigu, které se ukázaly jako efektivní nástroj voblasti pedagogického výzkumu. Konkrétně bylo vtéto části práce využito shlukové analýzy, korelační matice a analýzy hlavních komponent jako možných nástrojů pro ověření kvality navržených testů, respektive dovedností vtestech sledovaných.
Kvýzkumu byla využita data získána ztestování a zdotazníkového šetření vrámci projektu Testování žáků 1. ročníků oborů vzdělání poskytujících střední vzdělání smaturitní zkouškou 2008. Vrámci tohoto testování byla zjišťována úroveň osvojení různých dovednosti u téměř 7700 studentů vmatematice, českém jazyce, cizím jazyce a obecně studijních předpokladech. Tyto data byla použita jednak proto, že vnich bylo možné hledat další zajímavá fakta metodami data miningu ataké proto, že autor práce data již zpracovával v rámciprojektu, pro nějž byla data získána.
Vkaždém ze zkoumaných předmětů byli studenti testování vurčitých dovednostech. Některé dovednosti vrámci předmětu mohou mít mezi sebou větší či menší vazby. Pokud tyto vazby existují a bylo by možné je najít a vyspecifikovat, mohli bychom pak například prostřednictvím jedné dovednosti rozvíjet u studentů zároveň i dovednost druhou či optimalizovat testy redukcí počtu sledovaných dovedností.
1 Educational Data MiningVýzkum byl realizován zvelké části metodami data miningu. Data mining je proces, kterým získáváme -„dolujeme“ zajímavé, ale dosud neznámé informace z dat. Data miningové techniky mají široké uplatnění vkomerční sféře, ale protože poskytují řadu nesporných výhod, prosazují se například vlékařství, genetickém inženýrství či průmyslové sféře. Úspěšné a profitabilní využití data miningu otevřelo cestu uplatnění azdokonalení těchto technik i do jiných odvětví (Parr Rud, 2001).
Využití těchto technik pro analýzu dat z oblasti vzdělávání není dosud běžné. Nicméně tyto metody, na rozdíl od standardně používaných metod, jsou schopny vyspecifikovat všechny možné vazby nejen mezi dvěma atributy, ale i mezi skupinou atributů. Často mohou objevit i takové vazby, které bychom pomocí klasických metod ani neodhalili.
Podle Sparkse (2011) pro dolování dat ve vzdělávání (educational data mining) lze využít údajů shromážděných prostřednictvím běžných školních aktivit, a to jak některé typické údaje obsažené ve společných státních databázích, jako například výsledky testů adocházky tak i pomocné údaje, jako interakce studenta vlearning management systémech (viz např. Troszok, 2011) nebo délka reakce studenta na domácí úkoly.
Voblasti vzdělávání začal tedy získávat data mining na významu teprve nedávno. „Educational data mining“ (Dogan, Camurcu, 2007-2008) neboli dolování znalostí z dat ve vzdělávání či získaných vkontextu se vzděláváním je tedy poměrně novou výzkumnou oblastí, která nabízí zajímavé možnosti pro aplikaci různých metod data miningu. První mezinárodní konference na toto téma se konala v roce 2008 a první vědecký časopis snázvem Journal of Educational Data Mining se objevil v roce 2009.
1.1 Shluková analýzaCílem shlukové analýzy je zařazení objektů do skupin (shluků), a to především tak, aby dva objekty stejného shluku si byly více podobné, než dva objekty zrůzných shluků. Jestliže nám tedy není známá kategorizace objektů, je cílem najít takovou kategorizační strukturu, jež je ve shodě spoměry vdatech (Hendl, 2004).
„Shluková analýza hledá odpověď na otázku, zda lze pozorované příklady rozdělit do skupin (shluků) vzájemně si blízkých příkladů“ (Berka, 2003). Vychází se tedy ztoho, že umíme měřit vzdálenost mezi objekty určitého souboru.
Samotné míry vzdálenosti, ale závisí na měřítku veličin. Proto je důležité tyto veličiny normovat a to tak, že se konkrétní hodnota obvykle dělí nějakou jinou hodnotou: průměrem, směrodatnou odchylkou nebo rozpětím (max-min).
Shluková analýza je zastřešujícím názvem pro skupinu metod, které mají za cíl buď seskupit zadané objekty do shluků, nebo vytvořit hierarchii shluků objektů. Z používaných metod shlukové analýzy zmíním metodu hierarchického shlukování, jež byla vtéto práci využita.
Při hierarchické shlukové analýze rozlišujeme přístup (Řezanková, Húsek, Snášel, 2007) monotechnický, kdy jsou shluky na určité úrovni vytvářeny vždy pouze podle jedné zproměnných, a polytetický, při němž jsou brány vúvahu vždy všechny proměnné současně.
Dalším, jiným kritériem členění polytetického přístupu je to, zda jde o analýzu podobnosti (aglomerativní přístup), či nepodobnosti (divizní přístup).
U aglomerativního algoritmu se vychází ztoho, že každý objekt je samostatným shlukem. Tyto samostatné shluky jsou pak postupně po dvojicích spojovány od nejvíce podobných knejméně podobným, až je výsledkem jeden shluk.
Naopak divizní algoritmus vychází zpředpokladu, že na začátku všechny objekty tvoří jeden shluk. Tento shluk je následně postupně rozdělován až do stavu, kdy je každý objekt samostatným shlukem.
Vpráci bylo využito aglomerativních algoritmů, a to zejména těchto dvou:
Výstup shlukování lze zobrazit speciálním grafem, označovaným dendrogram. Jedná se ostromový diagram, který je znázorněním postupného shlukování jednak jednotlivých objektů, tak také shluků vytvořených vpředchozích krocích. Vzávislosti na programovém systému je dendrogram vytvářen buď vertikálně, nebo horizontálně. Podle zobrazení (vertikálního či horizontálního) jsou pak na jedné ose zobrazeny jednotlivé objekty a na druhé ose vzdálenost spojení.
Data byla shlukována na základě euklidovské míry (nejznámější metrika) vzdálenosti. Metrika vychází z geometrického modelu dat, kde objekty o n znacích chápeme jako body n-rozměrného Euklidovského prostoru En. Pak podobnost objektů můžeme vyjadřovat pomocí vzdálenosti jim odpovídajících bodů.
Shlukování bylo realizováno vprostředí R project, jenž je volně šiřitelným softwarovým prostředím pro statistické výpočty a grafické zobrazení získaných výstupů (R project, 2011).
1.2 Analýza hlavních komponentAnalýza hlavních komponent (PCA – principal component analysis) se zabývá problematikou redukce počtu proměnných pomocí tzv. hlavních komponent (Hendl, 2004). Pomocí hlavních komponent popisujeme variabilitu všech proměnných a vztahy mezi nimi. Hlavní komponenty jsou lineární kombinací původních proměnných. Zkoumání hodnot nových proměnných reprezentovanými hlavními komponentami místo původních hodnot umožňuje snadněji porozumět posuzovaným datům.
„Cílem analýzy je zp proměnných Xi vytvořit nové proměnné Zj (hlavní komponenty), jež jsou nekorelované“ (Hendl, 2004). Užitečnost nekorelovanosti spočívá vtom, že každá znových proměnných Zj měří jinou vlastnost (dimenzi) dat. Nové proměnné jsou navíc uspořádány podle svého rozptylu tak, že Var(Z1) > Var(Z2)>…>Var(Zp).
Postup při analýze hlavních komponent
1. Počáteční analýza – počáteční pohled na data, popisné statistiky a grafy.
2. Průzkum korelační matice – korelační matice představuje uspořádané korelace všech proměnných mezi sebou.
3. Provedení základních procedur analýzy hlavních komponent a rozhodnutí ovhodném počtu hlavních komponent.
Vstupní data a parametry analýzy:
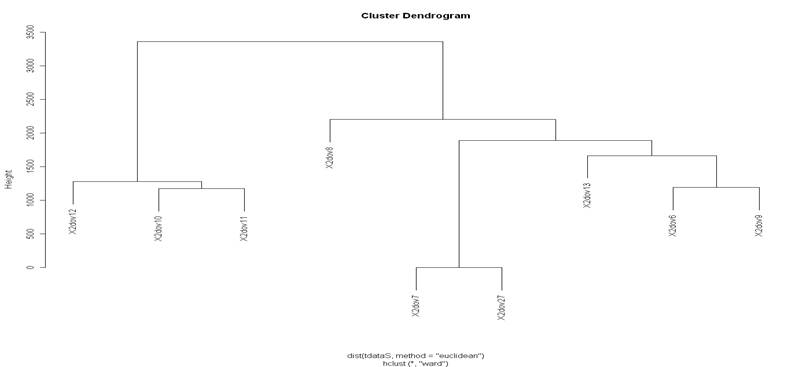
Obrázek 1: Dedrogram pro dovednosti z matematiky
Pokud výsledný dendrogram analyzujeme na hladině dvou shluků (height 2500), získáme dva samostatné shluky reprezentující dvě skupiny více si podobných dovedností zmatematiky.
První shluk je reprezentován dovednostmi:
Druhý shluk je pak tvořen dovednostmi:
Zdosažených výstupů můžeme konstatovat dílčí výsledek H31, že největší podobnosti jsou u dovedností:
Vzhledem kpodobnosti dovedností 2dov10 (Grafické vnímání a práce sgrafem) a 2dov11 (Poznání rovinných útvarů apráce snimi, prostorová představivost), 2dov7 (Numerické dovednosti) a 2dov27 (Numerické úlohy), 2dov6 (Chápání čísla jako pojmu vyjadřujícího kvantitu, zápis celku různými způsoby) a 2dov9 (Orientace a práce stabulkou) by každá dvojice těchto dovedností mohla být sloučena do jedné dovednosti. Tímto by se snížil počet sledovaných dovedností vmatematice z9 na 6 a zároveň by se snížil i počet otázek vtestu a tím i čas testování. Další možností je zanechat původní strukturu dovedností asledovat tyto dvojice nejvíce podobných dovedností současně, společnou skupinou testových otázek. Tímto by se opět redukoval počet testových otázek, a to způvodních dvou skupin pro každou dovednost na jednu skupinu pro obě dovednosti. Opět by došlo ike zkrácení času testování studentů.
2.2 Podobnosti mezi jednotlivými dovednostmi včeském jazyce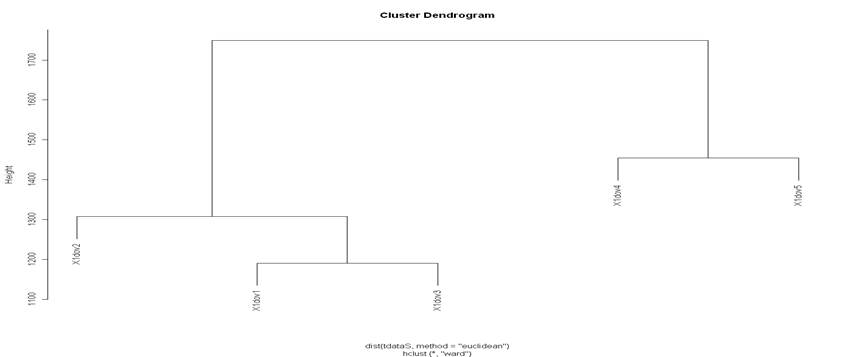
Obrázek 2: Dendrogram pro dovednosti zčeského jazyka
Při analýze výsledného dendrogramu pro předmět český jazyk na hladině dvou shluků (height 1500) získáme shluky reprezentující dvě skupiny více si podobných dovedností.
První shluk je reprezentován dovednostmi:
Druhý shluk je pak tvořen dovednostmi:
Zdosažených výstupů můžeme konstatovat dílčí výsledek H32, že vpřípadě redukce počtu dovedností by mohly být sjednoceny následující dvě skupiny nejvíce podobných dovedností:
Vzhledem kpodobnosti dovedností 1dov1 (Ovládání lexikálního pravopisu) a 1dov3 (Ovládání syntaktického pravopisu), 1dov4 (Třídění slov) a 1dov5 (Porozumění obsahu textu) by každá dvojice těchto dovedností mohla být sloučena do jedné dovednosti. Tímto by se snížil počet sledovaných dovedností včeském jazyce z5 na 3 a zároveň by se snížil ipočet otázek vtestu a tím i čas testování. Další možností je zanechat původní strukturu dovedností asledovat tyto dvojice nejvíce podobných dovedností současně, společnou skupinou testových otázek. Tímto by se opět redukoval počet testových otázek, a to způvodních dvou skupin pro každou dovednost na jednu skupinu pro obě dovednosti. Opět by došlo i ke zkrácení času testování studentů.
2.3 Podobnosti mezi jednotlivými dovednostmi vcizím jazyce

Obrázek 3: Dedrogram pro dovednosti zcizího jazyka
Zdendrogramu, jenž je výstupem shlukování dovedností zcizího jazyka lze konstatovat dílčí výsledek H33, že všechny sledované dovednosti vcizím jazyce spolu nevytváří shluky, skupiny dovedností, a že nelze identifikovat shluky podobnějších dovedností. Dovednosti vcizím jazyce jsou voleny dobře.
3 Korelace mezi všemi dovednostmi navzájemPro zjištění možných korelací mezi všemi sledovanými dovednostmi navzájem bude využito korelační matice a následně i metody analýzy hlavních komponent, která se často používá ke snížení dimenze dat sco nejmenší ztrátou informace pomocí tzv. hlavních komponent, kterými popisujeme variabilitu všech proměnných a vztahy mezi nimi.
3.1 Korelační matice|
1dov1 |
1dov2 |
1dov3 |
1dov4 |
1dov5 |
1dov30 |
2dov6 |
2dov7 |
2dov8 |
2dov9 |
2dov10 |
2dov11 |
2dov12 |
2dov13 |
2dov27 |
2dov31 |
5dov28 |
6dov29 |
0dov34 |
cjdov14 |
cjdov15 |
cjdov16 |
cjdov17 |
cjdov18 |
cjdov19 |
cjdovC |
|
|
1dov1 |
1 |
0.61 |
0.6 |
0.48 |
0.46 |
0.78 |
0.2 |
0.27 |
0.16 |
0.21 |
0.2 |
0.2 |
0.19 |
0.24 |
0.27 |
0.28 |
0.2 |
0.17 |
0.25 |
0.37 |
0.37 |
0.31 |
0.3 |
0.32 |
0.3 |
0.39 |
|
1dov2 |
0.61 |
1 |
0.58 |
0.48 |
0.68 |
0.81 |
0.24 |
0.32 |
0.2 |
0.25 |
0.26 |
0.27 |
0.25 |
0.3 |
0.32 |
0.35 |
0.26 |
0.22 |
0.33 |
0.39 |
0.38 |
0.31 |
0.31 |
0.35 |
0.31 |
0.41 |
|
1dov3 |
0.6 |
0.58 |
1 |
0.28 |
0.42 |
0.65 |
0.16 |
0.22 |
0.13 |
0.18 |
0.17 |
0.17 |
0.16 |
0.2 |
0.22 |
0.23 |
0.16 |
0.13 |
0.2 |
0.26 |
0.27 |
0.22 |
0.22 |
0.23 |
0.2 |
0.28 |
|
1dov4 |
0.48 |
0.48 |
0.28 |
1 |
0.6 |
0.75 |
0.31 |
0.38 |
0.2 |
0.31 |
0.31 |
0.35 |
0.27 |
0.36 |
0.38 |
0.41 |
0.31 |
0.25 |
0.38 |
0.47 |
0.45 |
0.37 |
0.38 |
0.42 |
0.37 |
0.49 |
|
1dov5 |
0.46 |
0.68 |
0.42 |
0.6 |
1 |
0.88 |
0.32 |
0.4 |
0.26 |
0.33 |
0.33 |
0.34 |
0.3 |
0.38 |
0.4 |
0.44 |
0.32 |
0.25 |
0.4 |
0.47 |
0.45 |
0.36 |
0.37 |
0.42 |
0.38 |
0.49 |
|
1dov30 |
0.78 |
0.81 |
0.65 |
0.75 |
0.88 |
1 |
0.33 |
0.42 |
0.26 |
0.34 |
0.34 |
0.35 |
0.31 |
0.39 |
0.42 |
0.45 |
0.33 |
0.27 |
0.42 |
0.52 |
0.5 |
0.41 |
0.41 |
0.46 |
0.42 |
0.54 |
|
2dov6 |
0.2 |
0.24 |
0.16 |
0.31 |
0.32 |
0.33 |
1 |
0.62 |
0.33 |
0.47 |
0.41 |
0.43 |
0.39 |
0.52 |
0.62 |
0.69 |
0.32 |
0.2 |
0.42 |
0.35 |
0.34 |
0.26 |
0.29 |
0.3 |
0.27 |
0.36 |
|
2dov7 |
0.27 |
0.32 |
0.22 |
0.38 |
0.4 |
0.42 |
0.62 |
1 |
0.6 |
0.5 |
0.51 |
0.58 |
0.67 |
0.76 |
1 |
0.89 |
0.36 |
0.23 |
0.56 |
0.42 |
0.42 |
0.34 |
0.35 |
0.36 |
0.32 |
0.44 |
|
2dov8 |
0.16 |
0.2 |
0.13 |
0.2 |
0.26 |
0.26 |
0.33 |
0.6 |
1 |
0.44 |
0.51 |
0.33 |
0.83 |
0.41 |
0.6 |
0.67 |
0.18 |
0.12 |
0.48 |
0.24 |
0.24 |
0.19 |
0.19 |
0.21 |
0.17 |
0.25 |
|
2dov9 |
0.21 |
0.25 |
0.18 |
0.31 |
0.33 |
0.34 |
0.47 |
0.5 |
0.44 |
1 |
0.77 |
0.51 |
0.45 |
0.49 |
0.5 |
0.71 |
0.32 |
0.21 |
0.44 |
0.34 |
0.31 |
0.24 |
0.26 |
0.28 |
0.24 |
0.33 |
|
2dov10 |
0.2 |
0.26 |
0.17 |
0.31 |
0.33 |
0.34 |
0.41 |
0.51 |
0.51 |
0.77 |
1 |
0.58 |
0.54 |
0.5 |
0.51 |
0.75 |
0.26 |
0.18 |
0.43 |
0.32 |
0.3 |
0.22 |
0.25 |
0.27 |
0.25 |
0.32 |
|
2dov11 |
0.2 |
0.27 |
0.17 |
0.35 |
0.34 |
0.35 |
0.43 |
0.58 |
0.33 |
0.51 |
0.58 |
1 |
0.57 |
0.65 |
0.58 |
0.77 |
0.32 |
0.2 |
0.49 |
0.36 |
0.33 |
0.26 |
0.27 |
0.3 |
0.27 |
0.36 |
|
2dov12 |
0.19 |
0.25 |
0.16 |
0.27 |
0.3 |
0.31 |
0.39 |
0.67 |
0.83 |
0.45 |
0.54 |
0.57 |
1 |
0.5 |
0.67 |
0.76 |
0.23 |
0.16 |
0.6 |
0.31 |
0.29 |
0.23 |
0.24 |
0.26 |
0.22 |
0.31 |
|
2dov13 |
0.24 |
0.3 |
0.2 |
0.36 |
0.38 |
0.39 |
0.52 |
0.76 |
0.41 |
0.49 |
0.5 |
0.65 |
0.5 |
1 |
0.76 |
0.84 |
0.36 |
0.23 |
0.49 |
0.39 |
0.38 |
0.31 |
0.32 |
0.33 |
0.3 |
0.4 |
|
2dov27 |
0.27 |
0.32 |
0.22 |
0.38 |
0.4 |
0.42 |
0.62 |
1 |
0.6 |
0.5 |
0.51 |
0.58 |
0.67 |
0.76 |
1 |
0.89 |
0.36 |
0.23 |
0.56 |
0.42 |
0.42 |
0.34 |
0.35 |
0.36 |
0.32 |
0.44 |
|
2dov31 |
0.28 |
0.35 |
0.23 |
0.41 |
0.44 |
0.45 |
0.69 |
0.89 |
0.67 |
0.71 |
0.75 |
0.77 |
0.76 |
0.84 |
0.89 |
1 |
0.39 |
0.25 |
0.63 |
0.45 |
0.43 |
0.35 |
0.36 |
0.39 |
0.34 |
0.46 |
|
5dov28 |
0.2 |
0.26 |
0.16 |
0.31 |
0.32 |
0.33 |
0.32 |
0.36 |
0.18 |
0.32 |
0.26 |
0.32 |
0.23 |
0.36 |
0.36 |
0.39 |
1 |
0.53 |
0.86 |
0.36 |
0.34 |
0.29 |
0.31 |
0.34 |
0.35 |
0.39 |
|
6dov29 |
0.17 |
0.22 |
0.13 |
0.25 |
0.25 |
0.27 |
0.2 |
0.23 |
0.12 |
0.21 |
0.18 |
0.2 |
0.16 |
0.23 |
0.23 |
0.25 |
0.53 |
1 |
0.73 |
0.3 |
0.3 |
0.28 |
0.27 |
0.29 |
0.29 |
0.34 |
|
0dov34 |
0.25 |
0.33 |
0.2 |
0.38 |
0.4 |
0.42 |
0.42 |
0.56 |
0.48 |
0.44 |
0.43 |
0.49 |
0.6 |
0.49 |
0.56 |
0.63 |
0.86 |
0.73 |
1 |
0.44 |
0.43 |
0.36 |
0.37 |
0.4 |
0.4 |
0.48 |
|
cjdov14 |
0.37 |
0.39 |
0.26 |
0.47 |
0.47 |
0.52 |
0.35 |
0.42 |
0.24 |
0.34 |
0.32 |
0.36 |
0.31 |
0.39 |
0.42 |
0.45 |
0.36 |
0.3 |
0.44 |
1 |
0.84 |
0.69 |
0.69 |
0.75 |
0.58 |
0.91 |
|
cjdov15 |
0.37 |
0.38 |
0.27 |
0.45 |
0.45 |
0.5 |
0.34 |
0.42 |
0.24 |
0.31 |
0.3 |
0.33 |
0.29 |
0.38 |
0.42 |
0.43 |
0.34 |
0.3 |
0.43 |
0.84 |
1 |
0.71 |
0.71 |
0.74 |
0.57 |
0.93 |
|
cjdov16 |
0.31 |
0.31 |
0.22 |
0.37 |
0.36 |
0.41 |
0.26 |
0.34 |
0.19 |
0.24 |
0.22 |
0.26 |
0.23 |
0.31 |
0.34 |
0.35 |
0.29 |
0.28 |
0.36 |
0.69 |
0.71 |
1 |
0.58 |
0.59 |
0.47 |
0.79 |
|
cjdov17 |
0.3 |
0.31 |
0.22 |
0.38 |
0.37 |
0.41 |
0.29 |
0.35 |
0.19 |
0.26 |
0.25 |
0.27 |
0.24 |
0.32 |
0.35 |
0.36 |
0.31 |
0.27 |
0.37 |
0.69 |
0.71 |
0.58 |
1 |
0.65 |
0.49 |
0.81 |
|
cjdov18 |
0.32 |
0.35 |
0.23 |
0.42 |
0.42 |
0.46 |
0.3 |
0.36 |
0.21 |
0.28 |
0.27 |
0.3 |
0.26 |
0.33 |
0.36 |
0.39 |
0.34 |
0.29 |
0.4 |
0.75 |
0.74 |
0.59 |
0.65 |
1 |
0.58 |
0.87 |
|
cjdov19 |
0.3 |
0.31 |
0.2 |
0.37 |
0.38 |
0.42 |
0.27 |
0.32 |
0.17 |
0.24 |
0.25 |
0.27 |
0.22 |
0.3 |
0.32 |
0.34 |
0.35 |
0.29 |
0.4 |
0.58 |
0.57 |
0.47 |
0.49 |
0.58 |
1 |
0.71 |
|
cjdovC |
0.39 |
0.41 |
0.28 |
0.49 |
0.49 |
0.54 |
0.36 |
0.44 |
0.25 |
0.33 |
0.32 |
0.36 |
0.31 |
0.4 |
0.44 |
0.46 |
0.39 |
0.34 |
0.48 |
0.91 |
0.93 |
0.79 |
0.81 |
0.87 |
0.71 |
1 |
Tabulka 1: Korelační matice
Za významné korelace byly označeny všechny, jejichž hodnota byla vyšší než 0,5. Tyto jsou vkorelační matici vyznačeny modře. Zkorelační matice je vidět, že jednotlivé dovednosti vrámci předmětu spolu korelují. Zajímavé jsou ale korelace dovedností mezi různými předměty (v korelační matici označeny žlutou barvou). Jedná se konkrétně onásledující korelace:
Zvýstupů získaných korelační maticí lze formulovat následující výsledky:
H34: Úspěšnost vobecně studijních předpokladech koreluje s matematickými dovednostmi studentů (korelační koeficient 0,63), zejména numerickými dovednostmi (korelační koeficient 0,56) a dovednostmi zaměřenými na práci sfunkcemi (korelační koeficient 0,6).
H35: Úroveň osvojení si dovedností studenty včeském jazyce koreluje s úrovní osvojení si některých dovedností studenty vcizím jazyce (korelační koeficient 0,54), zejména stavbou anglické/německé věty (korelační koeficient 0,52) aslovesnými strukturami (korelační koeficient 0,5).
3.2 Analýza hlavních komponentObrázek 4: Komponenty pro dovednosti
|
V1 |
V2 |
V3 |
V4 |
V5 |
V6 |
V7 |
V8 |
V9 |
V10 |
|
|
1dov1 |
0.155 |
0.1828 |
-0.3611 |
0.0217 |
-0.0915 |
-0.004 |
-0.2463 |
0.0355 |
-0.0076 |
0.5663 |
|
1dov2 |
0.1745 |
0.1573 |
-0.376 |
-0.0266 |
-0.048 |
0.0006 |
-0.0248 |
-0.042 |
-0.0048 |
-0.3833 |
|
1dov3 |
0.1254 |
0.1451 |
-0.3849 |
0.0058 |
-0.1332 |
0.0118 |
-0.5861 |
-0.0827 |
-0.0491 |
-0.0698 |
|
1dov4 |
0.1881 |
0.1213 |
-0.1849 |
-0.0171 |
0.1705 |
-0.0266 |
0.56 |
0.066 |
0.1271 |
0.4773 |
|
1dov5 |
0.1994 |
0.1269 |
-0.2798 |
-0.0287 |
0.0657 |
0.0032 |
0.3983 |
0.0431 |
-0.0027 |
-0.4809 |
|
2dov6 |
0.1803 |
-0.1577 |
0.0225 |
0.0399 |
0.272 |
-0.3015 |
-0.1353 |
0.6102 |
-0.0969 |
-0.0452 |
|
2dov7 |
0.2318 |
-0.2363 |
0.0102 |
0.0862 |
-0.0778 |
-0.3505 |
-0.0188 |
0.0438 |
-0.0043 |
0.016 |
|
2dov8 |
0.1628 |
-0.2635 |
-0.0095 |
0.0923 |
-0.5648 |
0.2158 |
0.1271 |
0.1819 |
-0.0489 |
0.0073 |
|
2dov9 |
0.1831 |
-0.1943 |
-0.0136 |
0.0385 |
0.3358 |
0.4751 |
-0.1285 |
0.2531 |
0.0239 |
-0.0052 |
|
2dov10 |
0.1851 |
-0.2229 |
-0.0252 |
0.081 |
0.236 |
0.5184 |
-0.0715 |
0.0333 |
-0.0028 |
0.0146 |
|
2dov11 |
0.1929 |
-0.1997 |
-0.0018 |
0.0369 |
0.2695 |
0.0426 |
-0.0049 |
-0.6271 |
0.0648 |
0.0274 |
|
2dov12 |
0.1897 |
-0.2707 |
-0.0034 |
0.0688 |
-0.4563 |
0.1443 |
0.1212 |
-0.121 |
-0.0239 |
0.0258 |
|
2dov13 |
0.2116 |
-0.2021 |
0.0027 |
0.0575 |
0.1928 |
-0.2981 |
-0.0647 |
-0.2917 |
0.0657 |
0.0043 |
|
2dov27 |
0.2318 |
-0.2364 |
0.0102 |
0.0862 |
-0.0778 |
-0.3505 |
-0.0188 |
0.0438 |
-0.0043 |
0.0161 |
|
5dov28 |
0.1634 |
0.0025 |
0.0978 |
-0.5431 |
0.0707 |
-0.0377 |
-0.0442 |
-0.001 |
-0.0963 |
-0.1268 |
|
6dov29 |
0.1288 |
0.0505 |
0.1066 |
-0.5757 |
-0.0315 |
0.0223 |
-0.0677 |
0.0506 |
0.2055 |
0.1483 |
|
1dov30 |
0.2202 |
0.1801 |
-0.38 |
-0.0145 |
0.0168 |
-0.0032 |
0.1507 |
0.0279 |
0.0175 |
-0.0113 |
|
2dov31 |
0.2524 |
-0.2756 |
-0.0008 |
0.0824 |
0.0722 |
-0.0373 |
-0.0399 |
-0.0258 |
0.0031 |
0.005 |
|
0dov34 |
0.2178 |
-0.0899 |
0.0936 |
-0.4913 |
-0.1562 |
0.0454 |
-0.0011 |
-0.0324 |
0.0117 |
-0.0062 |
|
cjdov14 |
0.2243 |
0.212 |
0.1975 |
0.122 |
-0.0018 |
0.0356 |
-0.0037 |
-0.0057 |
0.075 |
-0.0381 |
|
cjdov15 |
0.2208 |
0.2248 |
0.2078 |
0.1333 |
-0.0415 |
0.0151 |
-0.0434 |
0.016 |
0.1209 |
-0.0052 |
|
cjdov16 |
0.1853 |
0.21 |
0.2018 |
0.1092 |
-0.0742 |
-0.0004 |
-0.08 |
0.0082 |
0.3443 |
0.0127 |
|
cjdov17 |
0.1901 |
0.2065 |
0.217 |
0.1103 |
-0.0315 |
0.0177 |
-0.0689 |
0.0256 |
0.1921 |
-0.0727 |
|
cjdov18 |
0.2034 |
0.2181 |
0.2082 |
0.0997 |
-0.0194 |
0.0397 |
0.0025 |
-0.0151 |
-0.0987 |
-0.062 |
|
cjdov19 |
0.1774 |
0.1796 |
0.1553 |
-0.0071 |
0.0358 |
0.0227 |
0.0522 |
-0.1008 |
-0.8498 |
0.1221 |
|
cjdovC |
0.2392 |
0.2478 |
0.2332 |
0.1177 |
-0.0286 |
0.0269 |
-0.0263 |
-0.0096 |
-0.0183 |
-0.0126 |
Tabulka 2: Analýza hlavních komponent - vektory
Z analýzy hlavních komponent, lze formulovat dílčí výsledek H36, že na stanovení celkového obrazu o studentovi se podílejí všechny dovednosti. Tedy můžeme říct, že všechny jsou důležité a žádnou by nebylo dobré vyloučit. Také můžeme konstatovat, že ztohoto hlediska je i test dobře navržen.
Atributy s významnějším zastoupením u jednotlivých vektorů jsou označeny modře azeleně. Na základě získaných výstupů budou nejvýznamnější komponenty popsány:
· V1 – nejvýraznější rozdíly mezi studenty jsou podle všech dovedností, hodnoty zátěže jsou uvšech dovedností větší nebo rovny 0,1 => celkové „nadání“ pro všechny předměty,
· V2 – výrazně menší rozdíl vdovednostech, hodnoty zátěže jsou větší nebo rovny 0,1 u dovedností včeském a cizím jazyce, včetně celkové úspěšnosti u dovedností vtěchto předmětech => nadání pro český jazyk a cizí jazyk, nižší nadání pro matematiku,
Analýza hlavních komponent diferencuje studenty zhlediska jejich nadání a zvýstupů byly především definovány ty komponenty, kde byly výrazné zátěže vždy vcelé skupině dovedností vrámci předmětu.
4 ZávěrV této části výzkumu byly vpředmětech matematika a český jazyk nalezeny podmnožiny vzájemně si bližších dovedností vkaždém z předmětů U cizího jazyka bylo na dostupných datech zjištěno, že všechny dovednosti spolu do jisté míry souvisí a tvoří tak jednu množinu dovedností. Zdosažených výstupů byly naformulovány dílčí výsledky H31 (pro matematiku), H32 (pro český jazyk) aH33 (pro cizí jazyk).
Na základě výsledků získaných korelační maticí bylo nalezeno i několik významnějších korelací mezi dovednostmi zrůzných předmětů. Získané výstupy byly naformulovány ve výsledcích H34 a H35.
Dále bylo využito faktorové analýzy, která pomocí hlavních komponent popisuje variabilitu všech proměnných a vztahy mezi nimi. Jednotlivé komponenty byly následně interpretovány a zdosažených výsledků vyplynulo, že zhlediska sledovaných dovedností je test dobře navržen. Výstupy získané pomoci analýzy hlavních komponent jsou formulovány ve výsledku H36.
Zvýsledků získaných vrámci této části výzkumu jsou formulovány následující závěry adoporučení pro možné úpravy testu, respektive dovedností sledovaných v testu.
1. Revidovat jednotlivé dovednosti s případnou redukcí počtu dovedností či otázek vmatematice a včeském jazyce, a to na základě výstupů získaných při shlukování jednotlivých dovedností vrámci předmětu. Snížením počtu dovedností či redukcí počtu otázek vtestu u odpovídajících dovedností se samozřejmě zkrátí idélka testování.
2. Dovednosti vcizím jazyce jsou dobře zvolené.
3. Matematicky orientované dovednosti v obecně studijních předpokladech zakomponovat do testu zmatematiky a zjišťovat tak několik dovedností současně. Tím redukovat počet testových otázek a zkrátit dobu testování.
4. Vzhledem knalezeným korelacím mezi celkovou úspěšností studenta včeském jazyce adovednostmi vcizím jazyce, více propojovat výuku českého a cizího jazyka. Větší propojení výuky těchto dvou předmětů může studentům umožnit lepší vnímání, propojení apochopení řešené problematiky vobou jazycích (například výuka určité problematiky včeském jazyce a současně či návazně pak ivcizím jazyce).
5. Při ověřování kvality navržených testů zhlediska sledovaných dovedností využívat metodu analýzy hlavních komponent jako jednu zověřovacích metod.
6. Na základě získaných výstupů a poznatků dále optimalizovat testy. Další zajímavou možností, která by ale spíše mohla být předmětem dalšího výzkumu, je možnost rozvíjet jednu nebo několik dovedností, prostřednictvím jiné dovednosti. Podmínkou by samozřejmě bylo, aby všechny sledované dovednosti spolu souvisely (tvořily jeden shluk).
LiteraturaBERKA, P. Dobývání znalostí z databází. Praha: Academia, 2003. 366 s. ISBN 80-200-1062-9.
DOGAN, B.; CAMURCU, A.Y. Association Rule Mining from an Intelligent Tutor. Journal of Educational Technology Systems [online]. 2007-2008, v36 n4 p433-447 , [cit. 2011-02-22]. Dostupný z WWW: <http://baywood.metapress.com>.
HENDL, J. Přehled statistických metod zpracování dat. Praha: Portál, 2004. 584 s. ISBN 80-7178-820-1.
PARR RUD, O. Data Mining : Praktický průvodce dolováním dat pro efektivní prodej, cílený marketing a podporu zákazníků (CRM). Praha: Computer Press, 2001. 329 s. ISBN 80-7226-577-6.
ŘEZANKOVÁ, H.; HÚSEK, D.; SNÁŠEL, V. Shluková analýza dat. 1. vyd. Praha: Professional Publishing, 2007. 196 s. ISBN 978-80-86946-26-9.
SPARKS, S. D. Data Mining Gets Traction in Education. Education Week [online]. 2011, v30 n15 p1, [cit. 2011-02-22]. Dostupný z WWW: <http://www.edweek.org>.
TROSZOK, A. Dolování znalostí z dat v LMS systémech. Alternativní metody výuky 2011. 2011, 9. ročník, s. 52. ISBN 978-80-7435-104-4.
R [online]. 1997 [cit. 2011-04-26]. The R Project for Statistical Computing. Dostupné z WWW: <www.r-project.org>.
Aktuální číslo
Odborný vědecký časopis Trilobit | © 2009 - 2026 Fakulta aplikované informatiky UTB ve Zlíně | ISSN 1804-1795