
Ing. Iveta Žouželková
Ústav počítačových
a komunikačních systémů
Univerzita Tomáše
Bati ve Zlíně
Fakulta aplikované
informatiky
nám. T. G. Masaryka
5555, 760 01 Zlín, Česká republika
E-mail: zouzelkova@fai.utb.cz
Abstrakt
Příspěvek se zabývá popisem a srovnáním úspěšnosti predikce a robustnosti Data Miningových algoritmů implementovaných vSQL Serveru 2008 R2. Tato práce obsahuje sumarizaci odborných poznatků získaných při studiu prediktivních algoritmů a ověření jejich funkčnosti. Práce vychází zpoznatků publikovaných v MCTS Self-Paced Training Kit (Exam 70-448): Microsoft® SQL Server® 2008 - Business Intelligence Development and Maintenance a zabývá se Microsoft Decision Trees Algorithm, Microsoft Naive Bayes Algorithm, Microsoft Clustering Algorithm a Microsoft Neural Network Algorithm. Cílem práce bylo ověřit publikované výsledky a nabídnout ucelený pohled na principy predikce.
Abstract
This paper deals with the description and comparison of successful prediction and robustness of data mining algorithms implemented in SQL Server 2008 R2. This study contains a summary of expertise gained in the study of predictive algorithms and during verification of their functionality. The work is based on the findings published in the MCTS Self-Paced Training Kit (Exam 70-448): Microsoft ® SQL Server ® 2008 - Business Intelligence Development and Maintenance and deals with the Microsoft Decision Trees Algorithm, Microsoft Naive Bayes Algorithm, Microsoft and Microsoft Clustering Algorithm Neural Network Algorithm. The main aim of this work was to verify published results and offer a comprehensive view of the prediction principles.
Úvod
Data Mining je analytická metodologie získávání netriviálních a potenciálně užitečných informací zdat. Někdy se chápe jako analytická součást dobývání znalostí z databází (Knowledge Discovery in Databases, KDD), jindy se tato dvě označení chápou jako souznačná. Data Mining může být vnímán jako výsledek přirozeného vývoje vinformatice. Nárůst výpočetního výkonu počítačů a rozšířené používání databází vedlo kpotřebě data analyzovat. Takto získané informace a znalosti mohou být využity vkomerční sféře (kontrola produkce, analýza trhu, cílená reklama, profilování klientů, analýza nákupního košíku), ve výzkumu (analýza genetické informace, biomedicínská informatika) a dalších oblastech (vyhledávání teroristických hrozeb, monitorování aktivit na Internetu). [1]
Data Mining zahrnuje integrační techniky zrůzných disciplín, jako jsou např. databázové technologie, statistika, strojové učení (podoblast umělé inteligence), high-performance computing, neuronové sítě, vizualizační techniky a signal processing. [2]
Jednou zhlavních úloh Data Miningu je predikce hodnot budoucích vzávislosti na znalostech dat minulých. SQL Server 2008 R2 nabízí celou řadu prediktivních algoritmů. Lze predikovat diskrétní i spojité atributy. Tato práce nabízí přehled nejpoužívanějších algoritmů, popis jejich principu a srovnání úspěšnosti a robustnosti nabízených algoritmů při predikci.
Cílem této práce je sumarizace relevantních poznatků zoblasti použití prediktivních algoritmů a ověření výstupů publikovaných v MCTS Self-Paced Training Kit (Exam 70-448): Microsoft® SQL Server® 2008 - Business Intelligence Development and Maintenance (reference [9]).
1 Výběr vhodného algoritmu
Výběr vhodného algoritmu vždy závisí na konkrétní úloze a datech. Pokud se rozhodneme použít různé algoritmy na stejný problém, každý znich může vrátit různý výsledek, dokonce i vrámci jednoho algoritmu mohou vzniknout výsledky více než jednoho typu. [3]
SQL Server 2008 nabízí 4 základní algoritmy pro Data Miningovou predikci. Podle vhodnosti použití je lze rozdělit následovně:
Predikce diskrétního atributu:
Microsoft Decision Trees Algorithm
Microsoft Naive Bayes Algorithm
Microsoft Clustering Algorithm
Microsoft Neural Network Algorithm
Predikce spojitého atributu:
Microsoft Decision Trees Algorithm
2 Feature Selection
Feature Selection je nástroj, který využívají všechny algoritmy Data Miningu. Obecně vyhodnocuje, které atributy jsou pro danou analýzu relevantní. Vpřípadě že pracujeme svelkým množstvím sloupců, je třeba určit, které analýzu ovlivňují a které není třeba do analýzy zahrnout. Pokud bychom totiž pracovali se všemi sloupci, pak ty nepotřebné zbytečně zaměstnávají CPU a operační paměť během fáze učení a zbytečně zvětšují datový objem získaného modelu. Vždy se také naleznou sloupce, které by mohly zhoršit kvalitu výsledného modelu, protože jsou například zašuměné, neobsahují záznamy, nebo jsou naopak redundantní.
Feature Selection pracuje na principu přiřazování skóre atributům. Ty sloupce, které dosáhnou nejvyššího čísla, jsou pak zahrnuty do modelu. Tato funkce je vždy volána předtím, než je spuštěna učící fáze modelu a automaticky vyhodnotí vhodnost atributů pro daný model.
Analytické služby SQL Serveru 2008 R2 nabízejí několik metod pro Feature Selection. Zvolená metoda vždy záleží na vybraném algoritmu a jeho nastavených parametrech. [3]
2.1 Zajímavost (Interestingness score)
Využívá se kohodnocení sloupců, které obsahují nebinární spojitá numerická data
Založeno na výpočtu entropie vtom smyslu, že attributy, které mají náhodné rozdělení mají vyšší entropii a nižší informační hodnotu, proto takové atributy jsou méně zajímavé než ty ostatní.
Entropie každého atributu je porovnána sentropií všech dalších atributů následujícím způsobem: Interestingness(Attribute) = - (m - Entropy(Attribute)) * (m - Entropy(Attribute)), kdy m je celková entropie datové sady. [3]
2.2 Shannonova entropie
Využívá se kohodnocení sloupců, které obsahují diskrétní nebo diskretizovaná data
H(X) = -∑ P(xi) log(P(xi)) [3]
2.3 Bayesovská klasifikace
Využívá se kohodnocení sloupců, které obsahují diskrétní nebo diskretizovaná data
Jsou to datové struktury reprezentující proměnné a jejich vzájemné vztahy, které pracují na principu nezávislosti i podmíněné nezávislosti.
Bayesovská síť je acyklický orientovaný graf, ve kterém proměnné prostředí tvoří uzly a orientované spoje mezi uzly definují vztahy. Síť je tvořena dvěma typy uzlů: rodičem a potomkem.
Pro určení rodičů, potomků a jejich vzájemných vztahů jsou využívány dva algoritmy: K2 Prior a Uniform Prior [3]
2.4 Použití metod Feature Selection vzávislosti na algoritmu
|
Algoritmus |
Metoda |
Komentář |
|
Naive Bayes |
Shannon's Entropy Bayesian with K2 Prior Bayesian with uniform prior (default) |
The Microsoft Naïve Bayes algorithm accepts only discrete or discretized attributes; therefore, it cannot use the interestingness score. |
|
Decision trees |
Interestingness score Shannon's Entropy Bayesian with K2 Prior Bayesian with uniform prior (default) |
If any columns contain non-binary continuous values, the interestingness score is used for all columns, to ensure consistency. Otherwise, the default feature selection method is used, or the method that you specified when you created the model. |
|
Neural network |
Interestingness score Shannon's Entropy Bayesian with K2 Prior Bayesian with uniform prior (default) |
The Microsoft Neural Networks algorithm can use both methods, as long as the data contains continuous columns.
|
|
Clustering |
Interestingness score
|
The Microsoft Clustering algorithm can use discrete or discretized data. However, because the score of each attribute is calculated as a distance and is represented as a continuous number, the interestingness score must be used. |
Tab. 1: Použití metod Feature Selection vzávislosti na algoritmu [3]
3 Microsoft Decision Trees Algorithm
3.1 Obecný princip rozhodovacího stromu (Decision Tree Induction)
Způsob reprezentování znalostí vpodobě rozhodovacích stromů je dobře znám z řady oblastí. Indukce rozhodovacích stromů patří knejznámějším algoritmům zoblasti symbolických metod strojového učení. Při tvorbě rozhodovacího stromu se postupuje metodou „rozděl a panuj“. Trénovací data se postupně rozdělují na menší a menší podmnožiny tak, aby vtěchto podmnožinách převládaly příklady jedné třídy. [4]
Pseudokód algoritmu:
Zvol jeden atribut jako kořen dílčího stromu
Rozděl data vtomto uzlu na podmnožiny podle hodnot daného atributu
Přidej uzel pro každou podmnožinu
Existuje-li uzel, pro který nepatří všechna data do téže třídy, pak pro tento uzel opakuj 1, jinak konec.
Klíčovou otázkou algoritmu zůstává jaký atribut vybrat pro větvení stromu vbodě 1. Cílem je od sebe odlišit jednotlivé třídy stromu co nejlépe. Ktomu slouží entropie, nebo-li míra neurčitosti informace.

Vzor. 1: Základní vzorec pro výpočet entropie
Výpočet entropie pro jeden atribut se provádí tímto způsobem: Pro každou hodnotu v, kterou může atribut A nabývat, spočítej entropii H(A(v)). Hledáme atribut, pro něhož bude entropie nejnižší. Ten je tedy zvolen pro větvení stromu. [4]
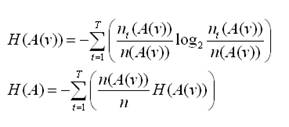
Vzor. 2: Výpočet entropie pro jeden atribut [4]
Numerické atributy
Stromy, které rozdělují objekty do tříd, se obvykle nazývají klasifikační. Vpřípadě numerických atributů musíme řešit velké množství hodnot. Nelze vytvořit pro každou hodnotu samostatnou větev. Pomocí se jeví rozdělení oboru hodnot na intervaly. Tyto intervaly pak lze považovat za diskrétní hodnoty atributu. Pokud dělíme na dva intervaly, jedná se o binarizaci. Při hledání dělícího bodu, kterým rozdělíme hodnoty do dvou intervalů se využívá opět entropie.
Existují ale i stromy regresní, které umožňují odhadovat hodnotu nějakého numerického atributu. Vlistových uzlech mají takové stromy místo názvu třídy například konkrétní hodnotu (konstantu), která odpovídá průměrné hodnotě cílového atributu pro příklady vtomto uzlu.
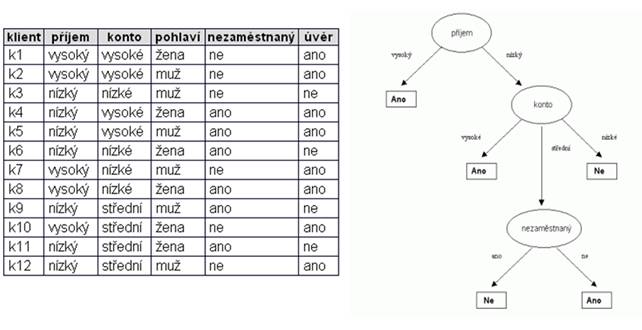
Obr. 1: Příklad vytvoření rozhodovacího stromu [5]
3.2. Algoritmus implementovaný vSQL Serveru 2008
Microsoft Decision Trees Algorithm se využívá vprediktivním modelování diskrétních i spojitých atributů.
Microsoft Decision Trees Algorithm vytváří Data Miningový model jako sérii větvení vtzv. uzlech. Algoritmus přidá uzel do modelu pokaždé, když vstupní sloupec významně koreluje spredikovaným sloupcem. Vytváření uzlů je také závislé na predikovaném sloupci – zda je diskrétní, nebo spojitý. Algoritmus využívá výše popsané funkce Feature Selection. [3]
Pro diskrétní atributy, algoritmus vytváří predikce založené na vztazích mezi vstupními sloupci datasetu. Využívá hodnot označovaných jako stavy (states) těchto sloupců a predikuje stavy sloupců označených jako prediktivní (predictable). Konkrétně, algoritmus identifikuje vstupní sloupce, které jsou v korelaci s predikovanými sloupci. Napříkladpředpoklad, že zákazník zakoupí jízdní kolo, pokud devět z deseti mladých zákazníků kolo zakoupí, ale jen dva z deseti starších zákazníků to také udělají, tak se dá předpokládat, že věk je dobrým ukazatelem nákupu kola. Rozhodovací strom předpovídá výsledek nákupu na základě této tendence (viz. obr. 2). [3]
Obr. 2: Příklad vytvoření nového uzlu ve stromě [3]
Pro spojité atributy algoritmus využívá lineární regresi kurčení, kde se rozhodovací strom bude větvit. Pokud je označeno více sloupců jako prediktivních, nebo pokud vstupní data obsahují vnořené tabulky (nested tables), které jsou označeny jako prediktivní, pak algoritmus vytvoří oddělený rozhodovací strom pro každý prediktivní sloupec. [3]
Výstup algoritmu
Dependency network ukazuje, které atributy (okolnosti) nejvíce ovlivňují zákazníka. Vtomto případě je rozhodující atribut Number Cars Owned, Region a Total Children.
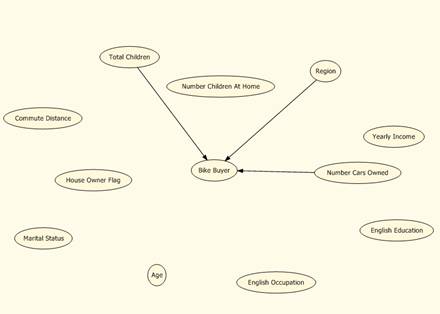
Obr. 3: Dependency Network
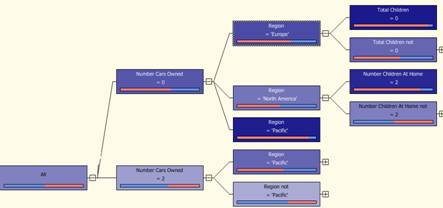
Obr. 4: Decision tree - část větvení
4 Microsoft Naive Bayes Algorithm
4.1 Obecný princip Bayesovské klasifikace (Bayesian classification)
Metody bayesovské klasifikace vycházejí zBayesovy věty o podmíněné pravděpodobnosti. Jedná se tedy o statistickou metodu, která je využívána kpredikci začlenění vzorku dourčité třídy. Bayesův vztah pro výpočet podmíněné pravděpodobnosti, že platí hypotéza H pokud pozorujeme evidenci E, má podobu [2,5]:

Vzor. 3: Bayesův vztah pro výpočet podmíněné pravděpodobnosti
Pro případ jedné evidence – Bayesova věta
Hypotéz je obvykle více (máme více klasifikačních tříd), proto nás pro danou evidenci zajímá pouze ta nejpravděpodobnější. Vzhledem ktomu, že nás zajímá, která hodnota aposteriorní pravděpodobnosti je maximální, ale ne už hodnota jako taková, lze vzorec zjednodušit:
![]()
Vzor. 4: Bayesův vztah pro danou evidenci
Toto zjednodušení nám umožní určit, která zhypotéz je pravděpodobnější, aniž by bylo třeba přesně spočítat aposteriorní pravděpodobnost obou hypotéz. Bayesova věta nám dává návod jak stanovit vliv jedné evidence na uvažovanou hypotézu. [2,5]
Pro případ více evidencí – Naivní bayesovský klasifikátor
Naivní bayesovský klasifikátor vychází zpředpokladu, že jednotlivé evidence E1,..., Ek jsou podmíněně nezávislé při platnosti hypotézy H. Aposteriorní pravděpodobnost je pak:
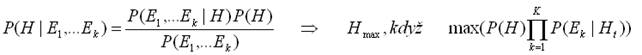
Vzor. 5: Výpočet aposteriorní pravděpodobnosti
Abychom mohli tento způsob klasifikace použít, potřebujeme znát hodnoty P(H) a P(Ek|H), které lze získat ztrénovacích dat ve fázi učení. Na rozdíl od jiných algoritmů se zde neprovádí prohledávání prostoru hypotéz. Stačí jen spočítat příslušné pravděpodobnosti na základě četnosti. Evidence Ek jsou hodnoty atributů Aj(vk), hypotézy H jsou cílové třídy C(vt).
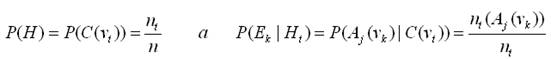
Vzor. 6: Výpočet aposteriorní pravděpodobnosti (2)
Přestože předpoklad podmíněné nezávislosti bývá vreálných úlohách jen málokdy splněn, vykazuje naivní bayesovský klasifikátor překvapivě úspěšnou klasifikaci. [2,5]
4.2 Algoritmus implementovaný vSQL Serveru 2008
Microsoft Naive Bayes algorithm je tedy založen na Bayesově teorému, který nebere vpotaz závislosti jednotlivých evidencí a proto je označován jako naivní. Díky tomu je tento algoritmus méně náročný na strojové zpracování a zajišťuje tak vytváření velmi rychlých datových náhledů.
Algoritmus vypočítává pravděpodobnost pro každý stav každého vstupního sloupce, že nabude některé zmožných hodnot predikovaného sloupce. Ztoho vyplývá, že tento algoritmus vyžaduje jeden klíčový sloupec, alespoň jeden predikovaný atribut a alespoň jeden vstupní atribut. Žádný ztěchto atributů nemůže být spojitý, takže pokud je vdatech obsažen spojitý atribut, bude ignorován, nebo diskretizován. Algoritmus využívá výše popsané funkce Feature Selection. [3]
Výstup algoritmu
Výstupem algoritmu je kromě Dependency Network také Attribute profiles, což je přehled jednotlivých atributů a četností výskytu žádané hodnoty vzávislosti na hodnotách vstupů.
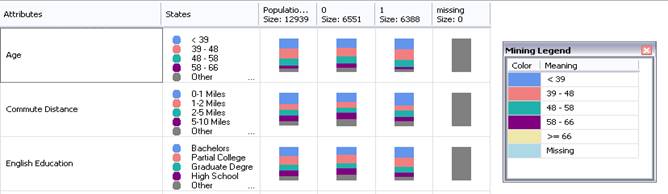
Obr. 5: Attribute profiles
Attribute Characteristic zobrazuje míru pravděpodobnosti, že predikovaný atribut nabude konkrétní hodnoty vzávislosti na hodnotách vstupních atributů. Např. obr. 6 ukazuje, že největší pravděpodobnost zakoupení kola je u zákazníků, kteří nemají děti.
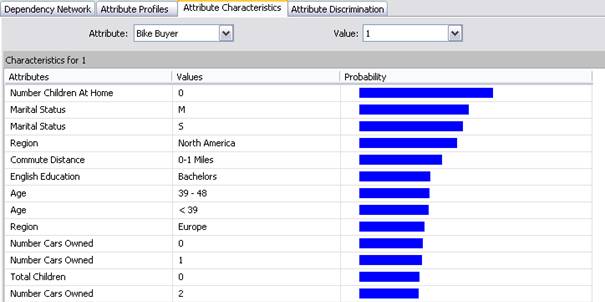
Obr. 6: Attribute Characteristic
5 Microsoft Neural Network Algorithm
5.1 Princip Neuronových sítí (Neural Networks)
Aplikace neuronových sítí vData Miningu se velmi rozšířila. Neuronové sítě se vyznačují tím, že mají mnohdy složitou strukturu, vyžadují dlouhý čas na naučení a interpretace výsledků (vah, jejichž nastavením se síť naučila) není triviální. Projevují však velkou toleranci k zašuměným datům a jsou schopny klasifikovat vzory, na které nebyly trénovány. To znich dělá ideální nástroj pro klasifikaci, shlukovou analýzu, a predikci.[2]
Dalším dobrým důvodem pro použití neuronových sítí je převaha numerických atributů. Zatímco stromy nebo pravidla jsou šity na míru kategoriálním datům a numerická data vyžadují diskretizaci, nyní je situace opačná. Pokud ale přesto chceme posuzovat kategoriální atribut, lze využít tzv. binarizace. Hodnota atributu A je 1 vpřípadě, že nabývá hodnoty vk, vopačném případě je hodnota 0. [5]
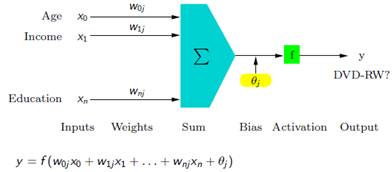
Obr. 7: Technický neuron [5]
Fungování umělých neuronových sítí je založeno na analogii se sítěmi biologickými. Základem je tedy jeden neuron, který má ováhované vstupy, obsahuje přenosovou funkci a jeden výstup (viz Obr. 1). Sítě se poté dělí podle toho, kolik mají vrstev (s jednou a více vrstvami), jaký mají algoritmus učení (s učitelem, bez učitele), a také podle stylu šíření (s dopředným šířením, zpětným šířením a svlastní organizací). [6] Mezi základní algoritmy patří algoritmus Backpropagation. Vdnešní době ale existuje mnoho dalších výkonnějších algoritmů jako jsou např. Levenberg-Matquart, Quazi-Newton, Resilient Backpropagation, Scaled Conjugate Gradient a další.
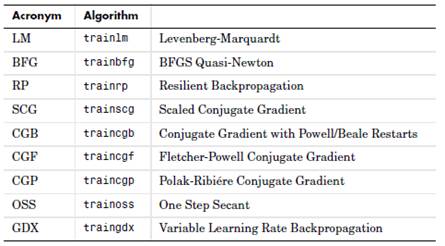
Obr. 8: Přehled algoritmů učení vícevrstvé sítě [6]
5.2 Algoritmus implementovaný vSQL Serveru 2008
Microsoft Neural Network Algorithm používá Vícevrstvý Perceptron, také známý jako gradientní backpropagation. Struktura sítě je tvořena třemi vrstvami neuronů: vstupní, skrytou a výstupní, přičemž mezi neurony nejsou žádná propojení uvnitř jednotlivých vrstev. [3]
Vstupní neurony – zajišťují vstup hodnot jednotlivých atributů
Pro spojité i diskrétní atributy – jeden vstupní neuron reprezentuje jednu hodnotu, které atribut nabývá
Pokud obsahuje atribut hodnoty null, pak je vytvořen jeden neuron schybějícím stavem
Každý vstup je ováhován vzávislosti na významu vstupu
Výstupní neurony – reprezentují výstup predikovaného atributu
Pro diskrétní vstupní atributy jeden výstupní neuron obvykle reprezentuje jeden predikovaný stav. Vpřípadě predikovaného atributu typu Boolean bude mít výstupní vrstva 3 neurony: jeden pro hodnotu true, jeden pro hodnotu false a jeden pro chybějící, nebo existující stav.
Diskrétní predikovaný sloupec, který nabývá více než dvou stavů generuje jeden výstupní neuron pro každý stav a jeden výstupní neuron pro chybějící, nebo existující stav.
Spojité predikované sloupce generují dva výstupní neurony: jeden shodnotou predikovaného sloupce a jeden schybějícím nebo existujícím stavem.
Pokud je vygenerováno více jak 500 výstupních neuronů, pak je vytvořena další síť. [3]
Přenosová funkce
Skrytá vrstva využívá hyperbolický tangent
Výstupní vrstva využívá sigmoidu
Trénování neuronové sítě
Trénování je ovlivněno velikostí trénovací množiny
Mining model může obsahovat více sítí vzávislosti na počtu sloupců, které jsou použity jako vstupní nebo predikované. Nejdřív je tedy určena komplexnost modelu.
Pro spojité atributy každý neuron reprezentuje rozsah hodnot, kterých může atribut nabývat. maximální počet stavů, které budou vytvořeny je definován parametrem MAXIMUM_STATES.
Lze také ovlivnit počet neuronů ve skryté vrstvě HIDDEN_NODE_RATIO.
Trénování probíhá podle principů Backpropagation
I v tomto algoritmu je využita Feature Selection pro určení zásadních parametrů pro vstup vpřípadě, že je jejich množství větší než MAXIMUM_INPUT_ATTRIBUTES.
Skórovací metody jsou využívány knormalizaci vstupních a výstupních hodnot tak, aby hodnoty, které se výrazně vychylují od ostatních (jedná se o extrémní hodnoty) neovlivnily výrazně celý model. [3]
Výstup algoritmu
Výstupem algoritmu je přehled stavů jednotlivých atributů a jejich vliv na rozhodovací proces. Dále je možné vtomto přehledu filtrovat podle stanovených kritérií.
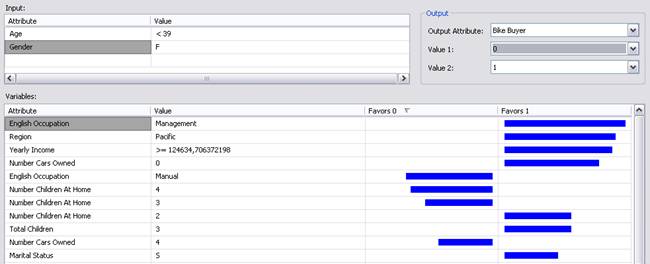
Obr. 9: Výstup Neural Network Algorithm
6 Microsoft Clustering Algorithm
6.1 Princip shlukové analýzy (Cluster Analysis)
Shluková analýza je vícerozměrná statistická metoda, která se používá ke klasifikaci objektů. Slouží k třídění jednotek do skupin (shluků) tak, aby si jednotky náležící do stejné skupiny byly podobnější než objekty ze skupin různých. Shlukovou analýzu je možné provádět jak na množině objektů, z nichž každý musí být popsán prostřednictvím stejného souboru znaků, které má smysl v dané množině sledovat, tak na množině znaků, které jsou charakterizovány prostřednictvím určitého souboru objektů, nositelů těchto znaků. [7]
Většinou se jedná o analýzu využívající učení bez učitele, protože na rozdíl od klasifikace, nemá předem určeny třídy, do kterých lze jednotlivé prvky zařadit.
6.2 Hierarchické metody
Hierarchické shlukování je systém podmnožin, kde průnikem dvou podmnožin - shluků je buď prázdná množina, nebo jeden z nich. Pokud nastane alespoň jednou druhý případ, je systém hierarchický. Tedy je to jakési větvení, zjemňování klasifikace. K hierarchickému shlukování lze přistupovat ze dvou stran – rozlišujeme přístup divizní (vycházíme z celku, jednoho shluku, a ten dělíme) a aglomerativní (vycházíme z jednotlivých objektů, shluků o jednom členu, a ty spojujeme). [7]
Metoda nejbližšího souseda (single linkage, nearest neighbor) – vzdálenost shluků je určována vzdáleností dvou nejbližších objektů z různých shluků. Při použití této metody jsou objekty taženy k sobě, výsledkem jsou dlouhé řetězy.
Pseudokód algoritmu:
Vypočítej matici nepodobnosti pro existující shluky (při prvním průchodu se bude jednat o jednotlivé objekty)
Zmatice nepodobnosti vyber dva shluky, které mají nejmenší vzdálenost a spoj je do nového shluku
Opakuj, dokud nevznikne jeden shluk

Obr. 10: Data zanesená do roviny(první obrázek), spočítaná matice nepodobnosti (prostřední obrázek) a výsledný dendrogram shlukování (poslední obrázek)[8]
Metoda nejbližšího souseda (complete linkage, furthest neighbor) - vzdálenost shluků je určována naopak vzdáleností dvou nejvzdálenějších objektů z různých shluků. Funguje dobře především v případě, že objekty tvoří přirozeně oddělené shluky, nehodí se, pokud je tendence k řetězení.
Centroidní metoda - vzdálenost shluků je určována vzdáleností jejich center (hypotetická jednotka s průměrnými hodnotami znaků). Může být nevážená nebo vážená. Ta zohledňuje velikosti klastrů a hodí se, pokud očekáváme jejich rozdílnost. Požaduje vyjádření vzdálenosti objektů čtvercovou euklidovskou vzdáleností.
Párová vzdálenost (pair-group average) - vzdálenost shluků je určována jako průměr vzdáleností všech párů objektů z různých shluků. Opět může být ve vážené i nevážené podobě.
Wardova metoda - vychází z analýzy rozptylu. Vybírá takové shluky ke sloučení, kde je minimální součet čtverců. Obecně lze říci, že je tato metoda velmi účinná, ale má tendenci tvořit poměrně malé shluky. Požaduje vyjádření vzdálenosti objektů čtvercovou euklidovskou vzdáleností.
6.3 Nehierarchické metody
Mějme databázi o n objektů, ze kterých chceme vytvořit kshluků, přičemž platí k≤n.
Metoda k-průměrů (K-Means)
Základní algoritmus funguje následovně: náhodně vybere kobjektů, které vprvní fázi označí za průměry shluků. Zbývající objekty jsou přiřazeny do shluků, které jsou jim nejblíže. Pak je znova spočítán průměr jednotlivých shluků. Tento proces pokračuje do té chvíle, dokud konverguje klíčová funkce - většinou kvadratická chyba.
Tato metoda je používána zvláště vpřípadech, kdy se ve skupině objektů nachází některý odlehlý objekt a je potřeba jej detekovat. [2]
Metoda k-medoidů (k-Medoid, Partiton around medoid)
Tento algoritmus je zvláště výhodný vpřípadě, že hodláme zanalyzovaných dat získat reprezentativní objekty, charakterizující jednotlivé shluky. To může být velmi výhodné při následné interpretaci výsledků. Zároveň lze říci, že tato metoda je vporovnání smetodou k-průměrů robustnější. [2]
6.4 Algoritmus implementovaný vSQL Serveru 2008
Microsoft Clustering Algorithm na rozdíl od ostatních algoritmů nepotřebuje předem stanovit predikovaný sloupec. Vychází to zprincipu shlukové analýzy, která data rozdělí do shluků na základě podobnosti. Ktomu využívá tento algoritmus dvou metod:
Expectation Maximization (EM)
Jedná se o pravděpodobnostní metodu, která propočítá pravděpodobnost toho, že bod náleží do daného clusteru pro všechny clustery.
Iterativně zpřesňuje pravděpodobnosti na základě vyhodnocování dalších bodů.
Jakmile pravděpodobnost toho, že bod náleží do clusteru, klesne pod stanovenou hranici, je bod zclusteru vyloučen.
Metoda umožňuje překrývání clusterů a mohou vznikat prázdné clustery.
K-Means
Tvrdá shluková metoda popsaná výše
Jeden datový bod může náležet pouze jednomu shluku
Funguje na principu minimalizace rozdílnosti dat a maximalizace vzdálenosti mezi shluky [3]
Výstup algoritmu
Výstupem algoritmu jsou shluky a jejich vzájemné vzdálenosti, které lze poté použít kpredikci.
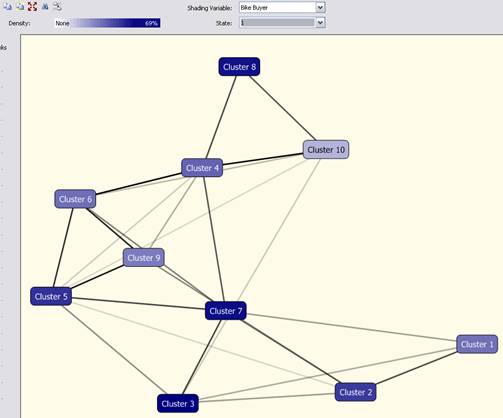
Obr. 11: Výstup Clustering Algorithm
7 Porovnání algoritmů pro predikci
7.1 Zdrojová data
Požadovaná data
Příprava dat
Pro srovnání úspěšnosti predikce byla použita testovací databáze AdwentureWorksDW2008R2, která je přizpůsobena ktěmto účelům a je dostupná zdarma na oficiálních stránkách Microsoft SQL Serveru 2008.
Pro testování Data Miningových nástrojů byl použit předpřipravený datový pohled dbo.vTargetMail, který obsahuje data o zákaznících fiktivní společnosti AdwentureWorks, která prodává jízdní kola. Obsahuje atributy popisující vlastnosti zákazníků a informaci o tom, zda kolo zakoupili, či nikoli.
Byl vytvořen projekt vBusiness Intelligence Development studiu, ve kterém byla vytvořena datová kostka obsahující několik vybraných atributů jako dimenze. Sloupec BikeBuyer obsahující informaci, zda zákazník koupil, či nekoupil kolo byl použit jako Measure. Na tuto kostku pak byly aplikovány Data Miningové algoritmy pro predikci.
Použité algoritmy pro predikci:
Microsoft Decision Trees Algorithm
Microsoft Naive Bayes Algorithm
Microsoft Neural Network Algorithm
Microsoft Clustering Algorithm
Obr. 12: Seznam atributů použitých vrámci dimenze pro vytvoření datové kostky
Základní statistika použitých dat
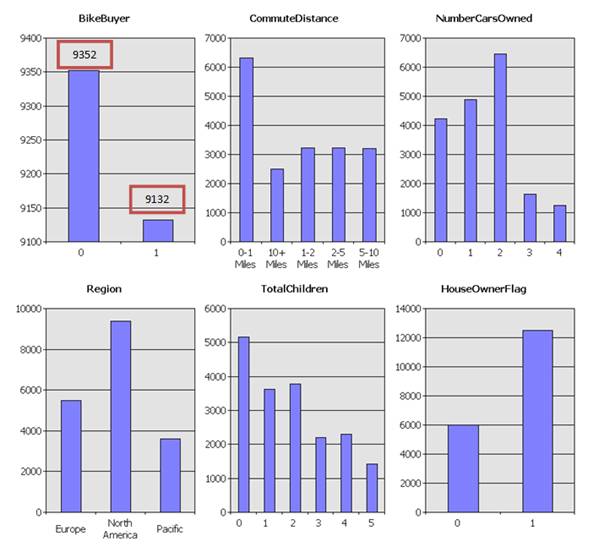
Obr. 13: Statistika použitých dat pro jednotlivé atributy
7.2 Cíle srovnání
Predikovat smaximální přesností chování zákazníka (zda kolo koupí, či nikoli)
Porovnat úspěšnost predikce jednotlivých algoritmů
Porovnat robustnost jednotlivých algoritmů
Pro všechny algoritmy byla sada dat rozdělena na dvě množiny: tréningová data 70% a testovací data 30%.
7.3 Srovnání úspěšnosti predikce algoritmů
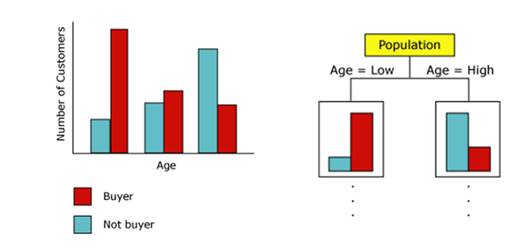
Níže umístěný graf ukazuje srovnání úspěšnosti predikce jednotlivých algoritmů. Osa x reprezentuje celkovou populaci zákazníků obchodu. Osa y reprezentuje ty zákazníky, kteří si zakoupí kolo – tzn. jedná se o cílovou skupinu zákazníků.
Křivka Ideal Model popisuje ideální stav vycházející zdat, že 50% zákazníků si zakoupí kolo. Pokud bychom tedy mohli předpovídat se 100% přesností, který zákazník zpopulace kolo zakoupí a který ne, pak by nám stačilo se zaměřit pouze na 50% populace.
Přímka Random Guess Model ukazuje náhodný výběr.
Data Miningové modely se pohybují súspěšností predikce mezi těmito křivkami a jsou tedy úspěšnější vpredikci, než náhodný model a méně úspěšné než ideální model. Nejvíce úspěšný je Decision Tree Algorithm, který při znalosti 50% populace je schopen predikovat s více jak 70% úspěšností.
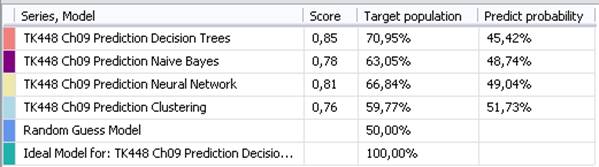
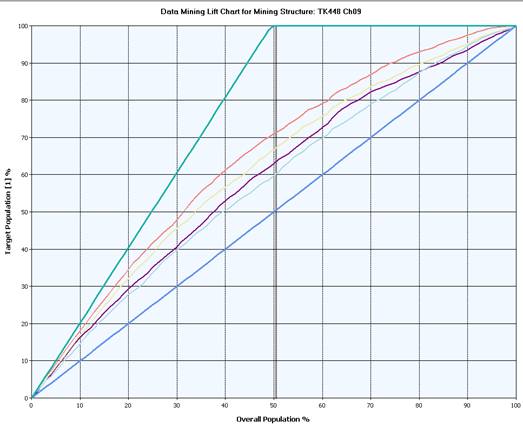
Obr. 14: Srovnání úspěšnosti algoritmů a křivek pro 100% úspěšnost a pro náhodný výběr
Následující graf ukazuje celkovou úspěšnost predikce pro konkrétní prediktivní modely:
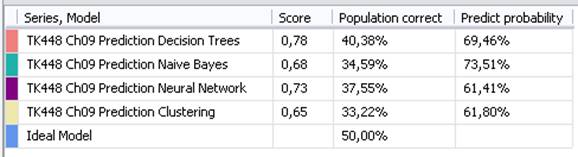
Obr. 15: Srovnání úspěšnosti algoritmů při predikci
7.4 Srovnání robustnosti algoritmů
Robustnost algoritmů je nejlépe ověřitelná pomocí křížové validace (Cross Validation), kdy je množina testovacích dat rozdělena na určitý počet skupin. Jedna skupina je určena na test a ty ostatní na trénování modelu. Výsledky každého modelu jsou poté vyhodnoceny pro správně predikované pozitivní (True Positive), správně predikované negativní (True Negative) stavy a na jejich opaky (False Positive, False Negative). Pro jednotlivé stavy je spočítána standardní odchylka, která udává robustnost modelu při predikci. [9] Model, který vykazuje nízkou standardní odchylku, je nejméně náchylný na skupinu vstupních dat a lze jej tedy použít svelkou úspěšnosti i na data, na která nebyl přímo trénován. Vtomto ohledu nejstabilnějších výsledků dosáhl Naive Bayes Algorithm.
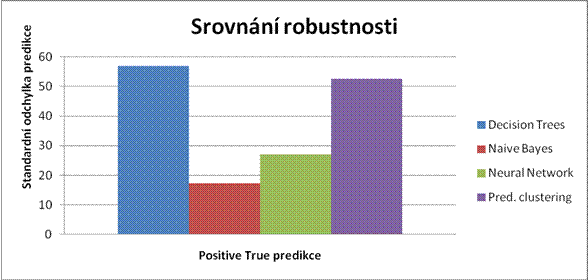
Obr. 16: Srovnání robustnosti algoritmů při predikci
8 Závěr
Cílem této práce bylo nabídnout rámcové srovnání obecných principů práce prediktivních algoritmů sreálně používanými algoritmy implementovanými vprostředí SQL Serveru 2008 R2. Výstupy, které byly získány při testování zkušební databáze AdwentureWorksDW2008R2, potvrdily úvodní tvrzení, že při opakované aplikaci jednoho algoritmu na stejnou sadu dat vznikají rámcově rozdílné výsledky. Všechny algoritmy vykazovaly tyto výstupní odlišnosti oproti zjištěním publikovaným v [9], což je logické. Na začátku dochází krozdělení dat na množinu tréninkovou a množinu testovací. Vpřípadě, že se liší tréninkové množiny porovnávaných aplikací algoritmu, liší se vždy částečně i získané výstupy. Výsledek je také závislý na poměru těchto dvou množin, kde by se také nabízelo další porovnání úspěšnosti algoritmů.
Výsledné srovnání úspěšnosti predikce splnilo publikovaný předpoklad. Nejúspěšnější je Decision Tree Algorithm, který je při znalosti 50% populace schopen predikovat s více jak 70% úspěšností. Na druhou stranu právě tento algoritmus vykazuje nejvyšší standardní odchylku a je tedy nejvíce náchylný na vstupní data.
9 Poděkování
Článek vznikl za finanční podpory Interní grantové agentury Univerzity Tomáše Bati číslo IGA/FAI/2012/036.
10 Reference
[1] Data Mining. In Wikipedia : the free encyclopedia [online]. St. Petersburg (Florida): Wikipedia Foundation, 1.11.2005, last modified on 7. 3. 2010 [cit. 2010-05-24]. Dostupné z WWW: <http://cs.wikipedia.org/wiki/Data_mining>.
[2] HAN, Jiawei; KAMBER, Micheline. Data Mining : Concepts and Techniques. San Diego: Academic Press, 2001. 550 s. ISBN 1-55860-489-8.
[3] MSDN Library: Data Mining Algorithms (Analysis Services - Data Mining). MICROSOFT. Msdn.microsoft.com [online]. 2008, 2012 [cit. 2012-01-20]. Dostupné z: http://msdn.microsoft.com/en-us/library/ms175595.aspx
[4] Data Mining [online]. 2009 [cit. 2010-05-24]. MGedata. Dostupné z WWW: <http://www.mgedata.com/cz/kvalifikace/data-mining>.
[5] BERKA, Petr. Dobývání znalostí z databází. Praha: Academia, 2003. 366 s. ISBN 80-200-1062-9.
[6] DEMUTH, Howard; BEALE, Mark; HAGAN, Martin. Matlab : Neural Network Toolbox 6 - User. Natick: The MathWorks, Inc., 2009. 906 s.
[7] Shluková analýza. In Wikipedia : the free encyclopedia [online]. St. Petersburg (Florida): Wikipedia Foundation, 10.1.2007, last modified on 6.4.2010 [cit. 2010-05-29]. Dostupné z WWW: <http://cs.wikipedia.org/wiki/Shlukov%C3%A1_anal%C3%BDza>.
[8] HANUŠ, Jan. Shluková analýza a její aplikace. Plzeň, 2009. 42 s. Bakalářská práce. Západočeská univerzita v Plzni, Fakulta aplikovaných věd, Katedra matematiky.
[9] VEERMAN, Erik, et al. MCTS Self-Paced Training Kit (Exam 70-448): Microsoft® SQL Server® 2008 - Business Intelligence Development and Maintenance. United States : Microsoft Press, 2009. 688 s. ISBN 0-7356-2636-7, 9780735626362.
Aktuální číslo
Odborný vědecký časopis Trilobit | © 2009 - 2026 Fakulta aplikované informatiky UTB ve Zlíně | ISSN 1804-1795